---
title: "My Document"
execute:
echo: true
---Homework 5
Key
Click link above for answers to homework 5.
Data
Instructions
Answer each of the following questions. Be sure to display all your code in the rendered version (use echo: true throughout1).
1 You can make this a global option for your whole document by putting it directly in the YAML of your qmd:
Exercises
- Download the
billboarddata set introduced in lecture (above) to the same folder where you’re saving your qmd for this homework2. - Read in the data, clean up the names, and pivot it in a way so the first few rows look like this:
2 If your project directory is different from the directory where you’ll be saving these two files, you should use the here() package to be able to run code interactively and knit your .qmd without conflict
> # A tibble: 5,307 × 6
> artist track time date_entered week rank
> <chr> <chr> <time> <date> <int> <dbl>
> 1 2 Pac Baby Don't Cry (Keep... 04:22 2000-02-26 1 87
> 2 2 Pac Baby Don't Cry (Keep... 04:22 2000-02-26 2 82
> 3 2 Pac Baby Don't Cry (Keep... 04:22 2000-02-26 3 72
> 4 2 Pac Baby Don't Cry (Keep... 04:22 2000-02-26 4 77
> 5 2 Pac Baby Don't Cry (Keep... 04:22 2000-02-26 5 87
> 6 2 Pac Baby Don't Cry (Keep... 04:22 2000-02-26 6 94
> 7 2 Pac Baby Don't Cry (Keep... 04:22 2000-02-26 7 99
> 8 2Ge+her The Hardest Part Of ... 03:15 2000-09-02 1 91
> 9 2Ge+her The Hardest Part Of ... 03:15 2000-09-02 2 87
> 10 2Ge+her The Hardest Part Of ... 03:15 2000-09-02 3 92
> # ℹ 5,297 more rows- Create a variable named
datethat corresponds to theweekbased on thedate_entered3. Read the footnote for a hint but if you need help visualizing what the final dataset might look like, you can reveal another hint below.
3 For instance, if the date_entered is 1-13-2000 and week is 1, then when week is 2 date will have a value of 1-20-2000. Hint: Try using if_else() here.
- Create a dataset of the song(s) with the most weeks in the top 3 by month of 20004. The final dataset should look like this:
4 It’ll be helpful here to create month and year indicator variabels that use to specify a necessary logical condition and/or use to group your dataset for certain steps. Hint: There are many ways to arrive at this answer but one approach uses the functions mutate, if_else, slice_max, distinct, and arrange.
> # A tibble: 19 × 4
> month artist track peak_weeks
> <dbl> <chr> <chr> <dbl>
> 1 1 Aguilera, Christina What A Girl Wants 3
> 2 2 Savage Garden I Knew I Loved You 4
> 3 3 Lonestar Amazed 4
> 4 4 Hill, Faith Breathe 5
> 5 4 Santana Maria, Maria 5
> 6 5 Hill, Faith Breathe 4
> 7 5 Santana Maria, Maria 4
> 8 6 Aaliyah Try Again 2
> 9 6 Anthony, Marc You Sang To Me 2
> 10 6 Hill, Faith Breathe 2
> 11 6 Santana Maria, Maria 2
> 12 6 Vertical Horizon Everything You Want 2
> 13 7 Aaliyah Try Again 4
> 14 8 Sisqo Incomplete 4
> 15 8 matchbox twenty Bent 4
> 16 9 Janet Doesn't Really Matte... 5
> 17 10 Madonna Music 4
> 18 11 Creed With Arms Wide Open 4
> 19 12 Destiny's Child Independent Women Pa... 5- Pick one month of 2000 and visualize the entire charting trajectory of the songs that spent at least 1 week in the top 3 during that month. Hint: start with the data set created in question 3. An example of what this could look like for April is provided below.
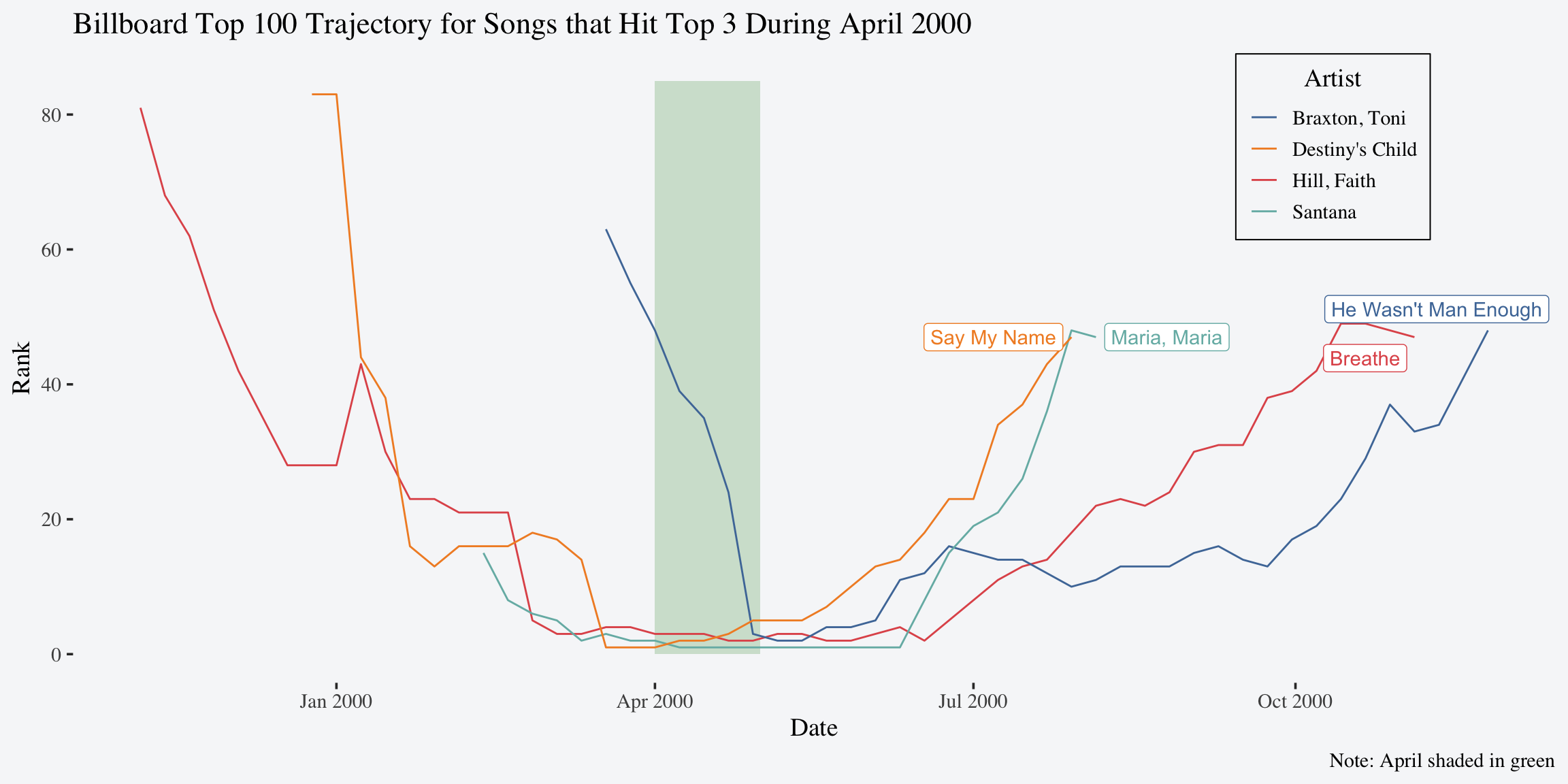
Note: This example plot is an extremely specified and polished version of what this can look like. There are a number of ways this can look and you should not be graded nor grade lower for aesthetic features that many of you are still learning. The takeaway here is to challenge yourself to figure out the code to create something that can plot the entire trajectory of the songs that reached the top 3 in whatever month you choose. This will require a combination of the skills you’ve learned in this class thus far. Try this with the content available from lecture first. If you get stuck, there is a hint you can reveal below.
Due Dates
| # | Homework Due | Peer Review Due |
|---|---|---|
| 1 | 7 October | 12 October |
| 2 | 14 October | 19 October |
| 3 | 21 October | 26 October |
| 4 | 28 October | 2 November |
| 5 | 11 November1 | 16 November |
| 6 | 18 November | 23 November |
| 7 | 25 November | 30 November |
| 8 | 2 December | 7 December |
| 9 | 9 December | 14 December |
| 1 You will have two weeks to complete Homework 5 | ||