Sampling distributions,
Central limit theorem,
& the Logic of inference
SOC 221 • Lecture 5
Monday, July 7, 2025

Imagine drawing ONE sample from the population and calculating the sample mean
Imagine drawing ONE sample from the population and calculating the sample mean
Just by chance, our sample mean may be a little different than the true population mean.
Distance between the sample mean and the actual population mean reflects random sampling error

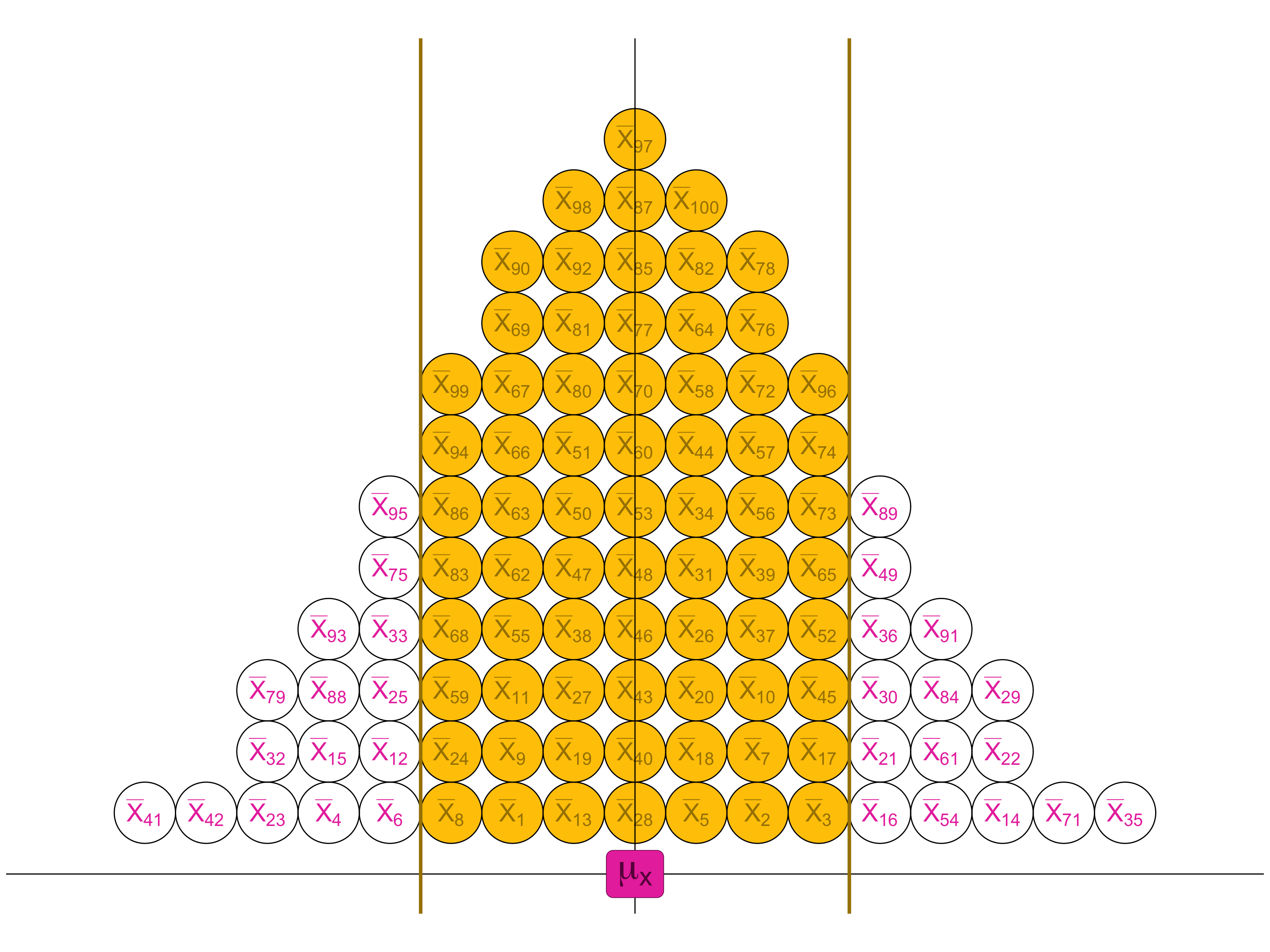
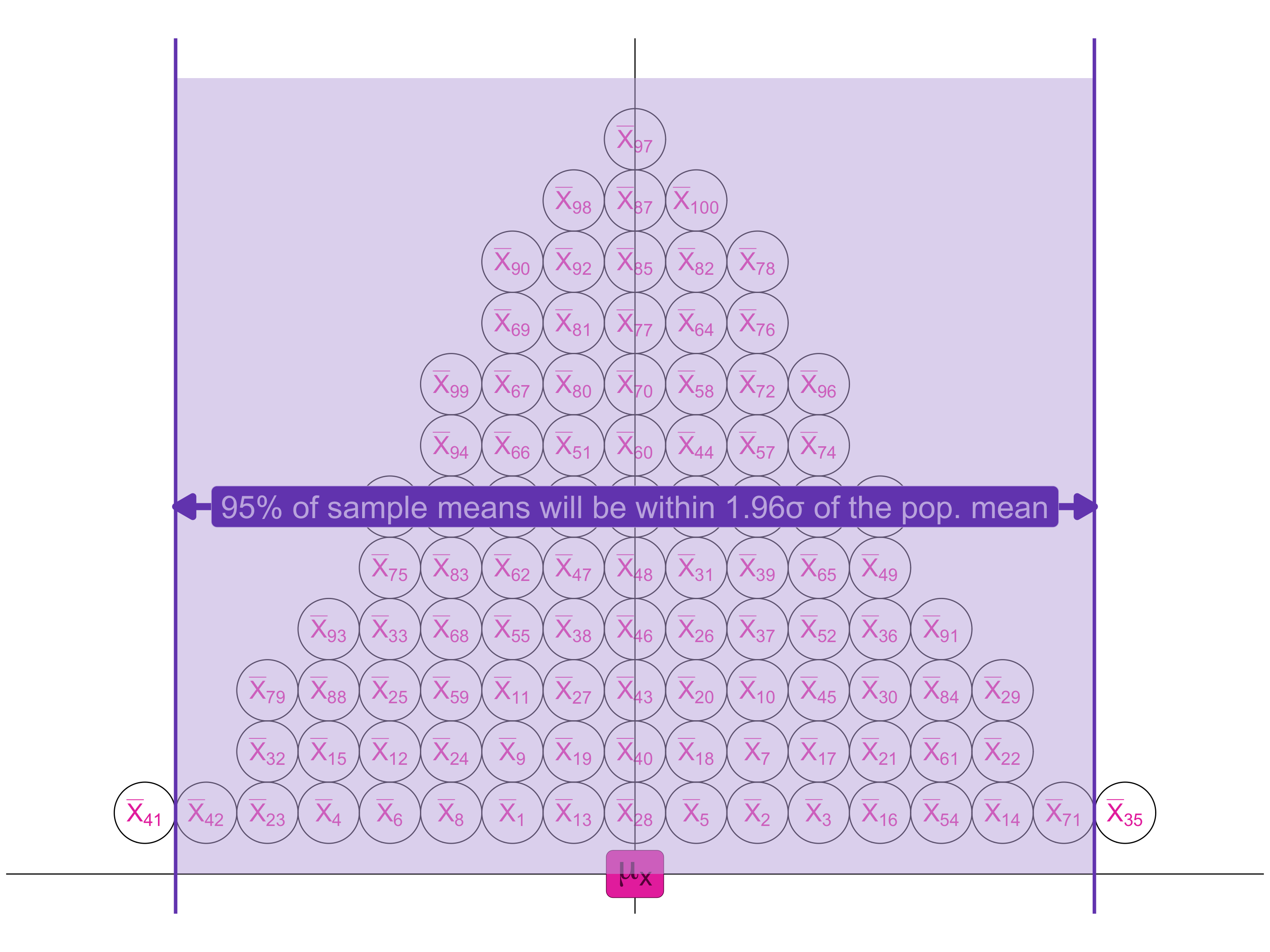
Now imagine drawing LOTS of independent samples and calculating the mean of X for each one.

Interesting features of the
sampling distribution
(when certain conditions are met):
• Normal distribution
• Mean of the sampling distribution is equal to the population mean
This produces a SAMPLING DISTRIBUTION of sample means

So can use what we know about the normal distribution to think about the location of sample means relative to the population mean.
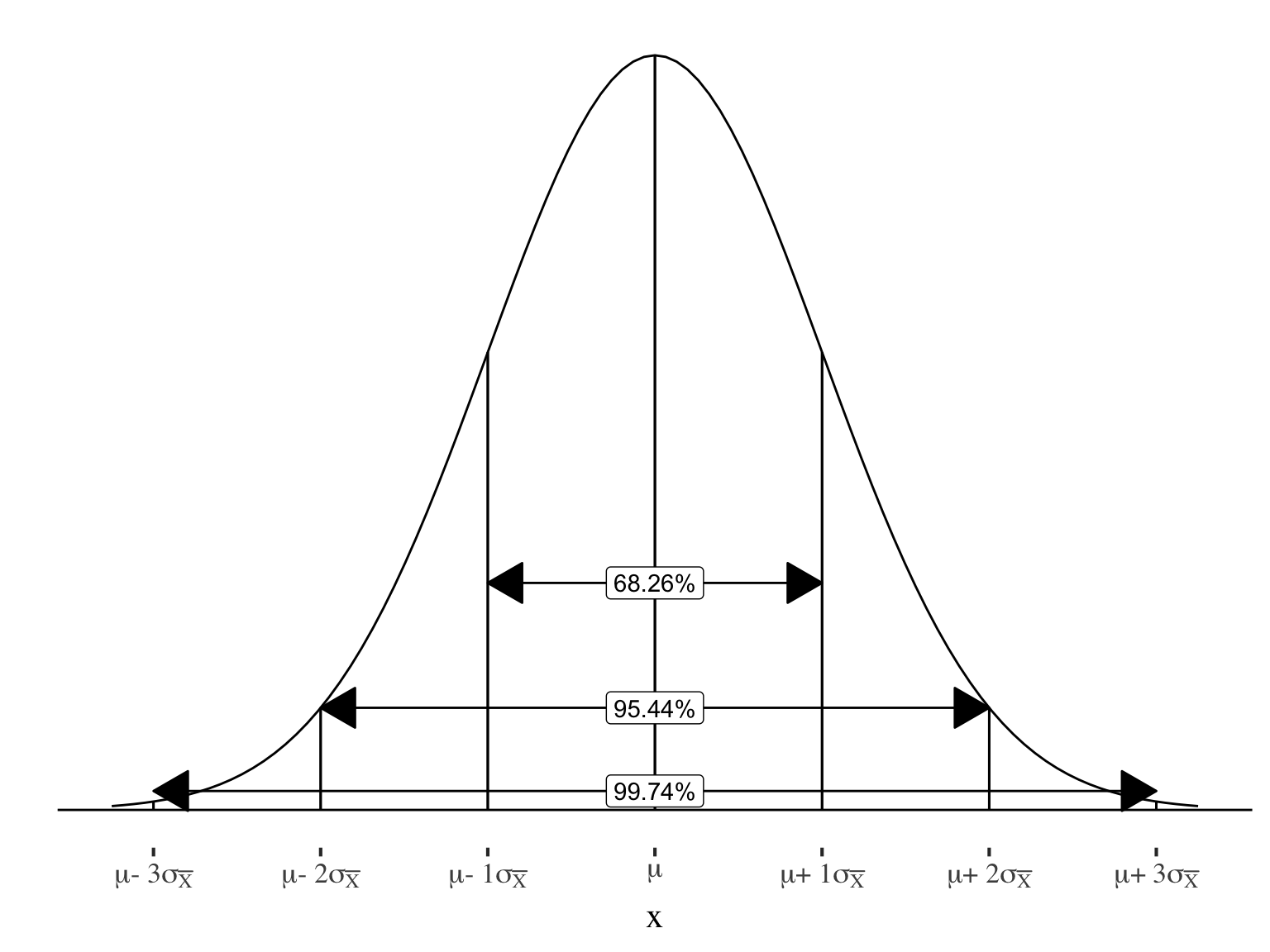
68.26% of samples will be within 1 \(\sigma\) of the pop. mean
95% of sample means will be within 1.96 \(\sigma\) of the pop. mean
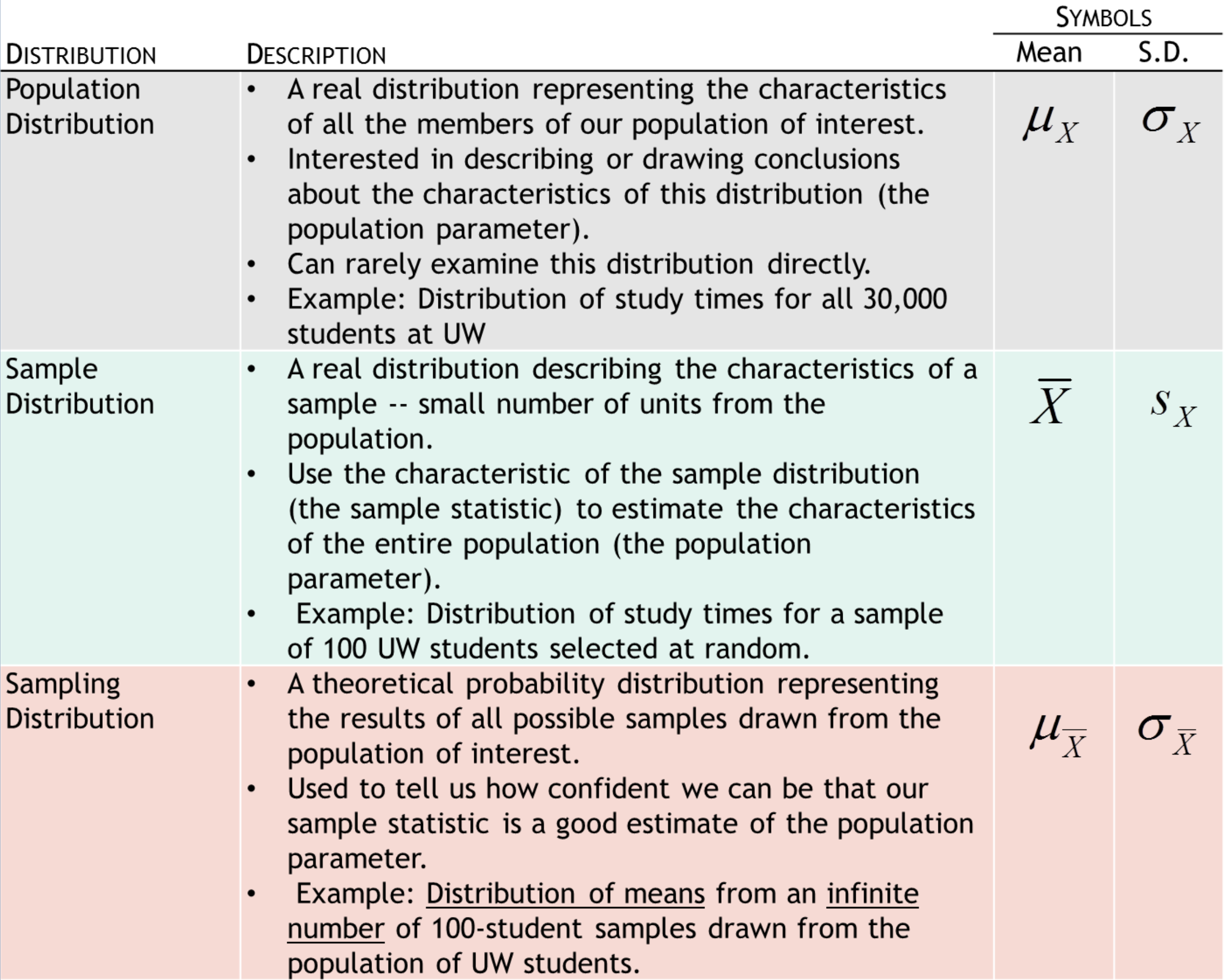
Three types of distributions
Implication of central limit theorem
- Central limit theorem tells us that if the size of our random sample is large enough, we can assume that the sampling distribution of all such possible samples is:
- Normally distributed
- Mean: \(\mu_\bar{X}\) \(= \mu_X\)
- Standard Error = \(\sigma_\bar{X}\) \(= \frac{\sigma}{\sqrt{n}}\)
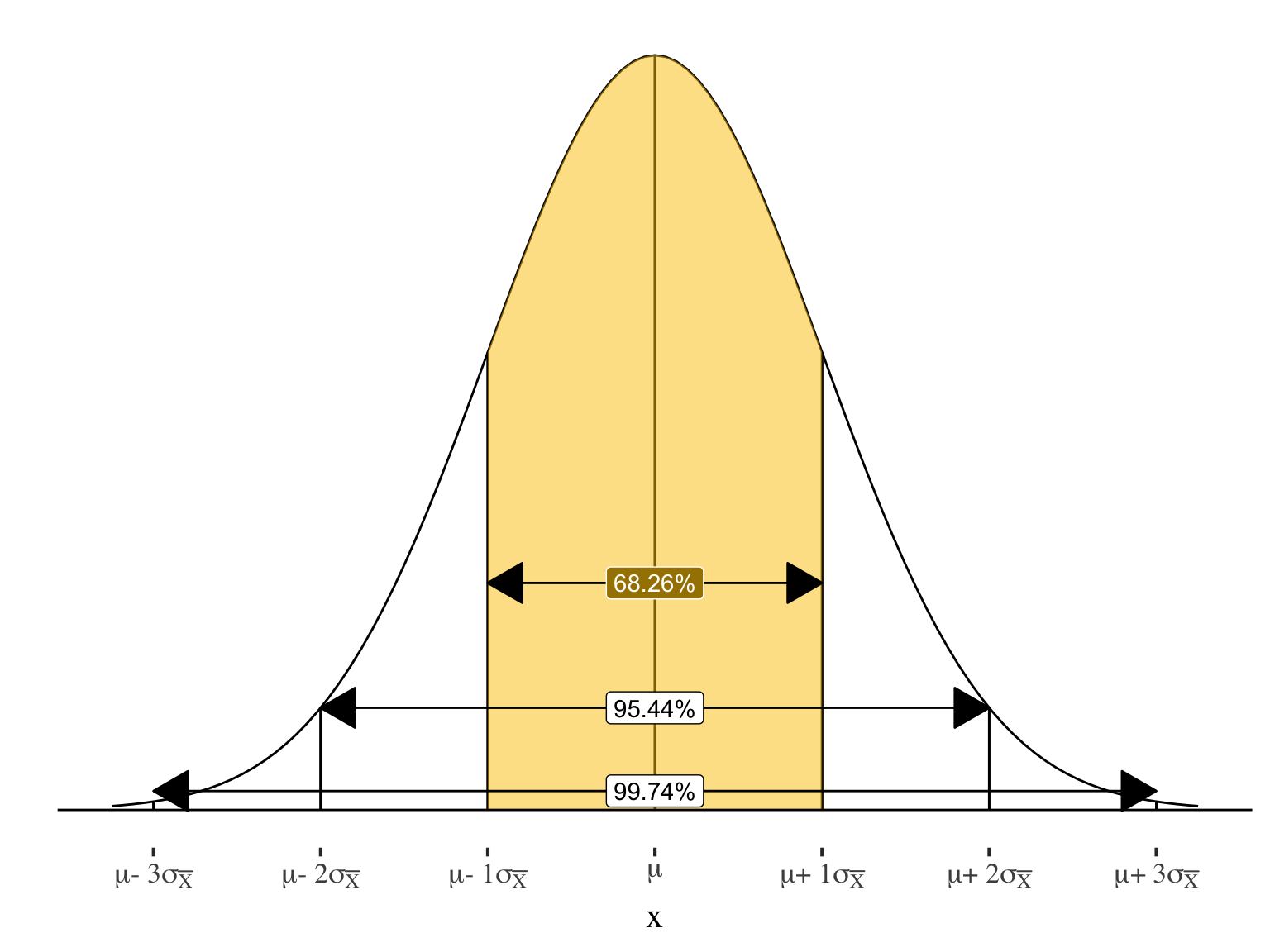
Just over 68% of sample means will be within ±1 standard error of the true population mean
Implication of central limit theorem
- Central limit theorem tells us that if the size of our random sample is large enough, we can assume that the sampling distribution of all such possible samples is:
- Normally distributed
- Mean: \(\mu_\bar{X}\) \(= \mu_X\)
- Standard Error = \(\sigma_\bar{X}\) \(= \frac{\sigma}{\sqrt{n}}\)
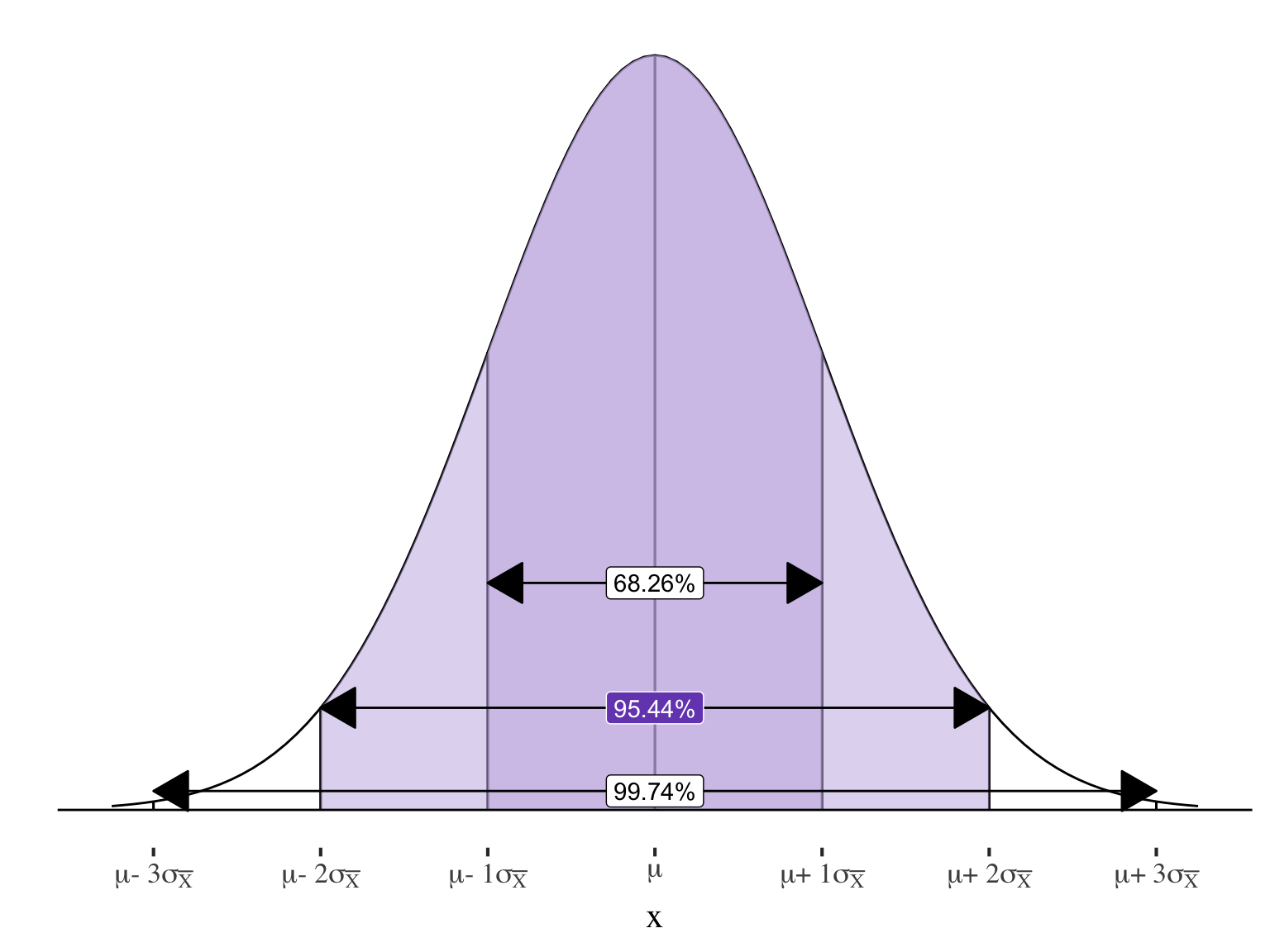
\(95.44\%\) of sample means will be within \(\pm2\) standard errors of the true population mean
And exactly \(95\%\) will be within \(1.96\) standard errors
Implication of central limit theorem
- Central limit theorem tells us that if the size of our random sample is large enough, we can assume that the sampling distribution of all such possible samples is:
- Normally distributed
- Mean: \(\mu_\bar{X}\) \(= \mu_X\)
- Standard Error = \(\sigma_\bar{X}\) \(= \frac{\sigma}{\sqrt{n}}\)
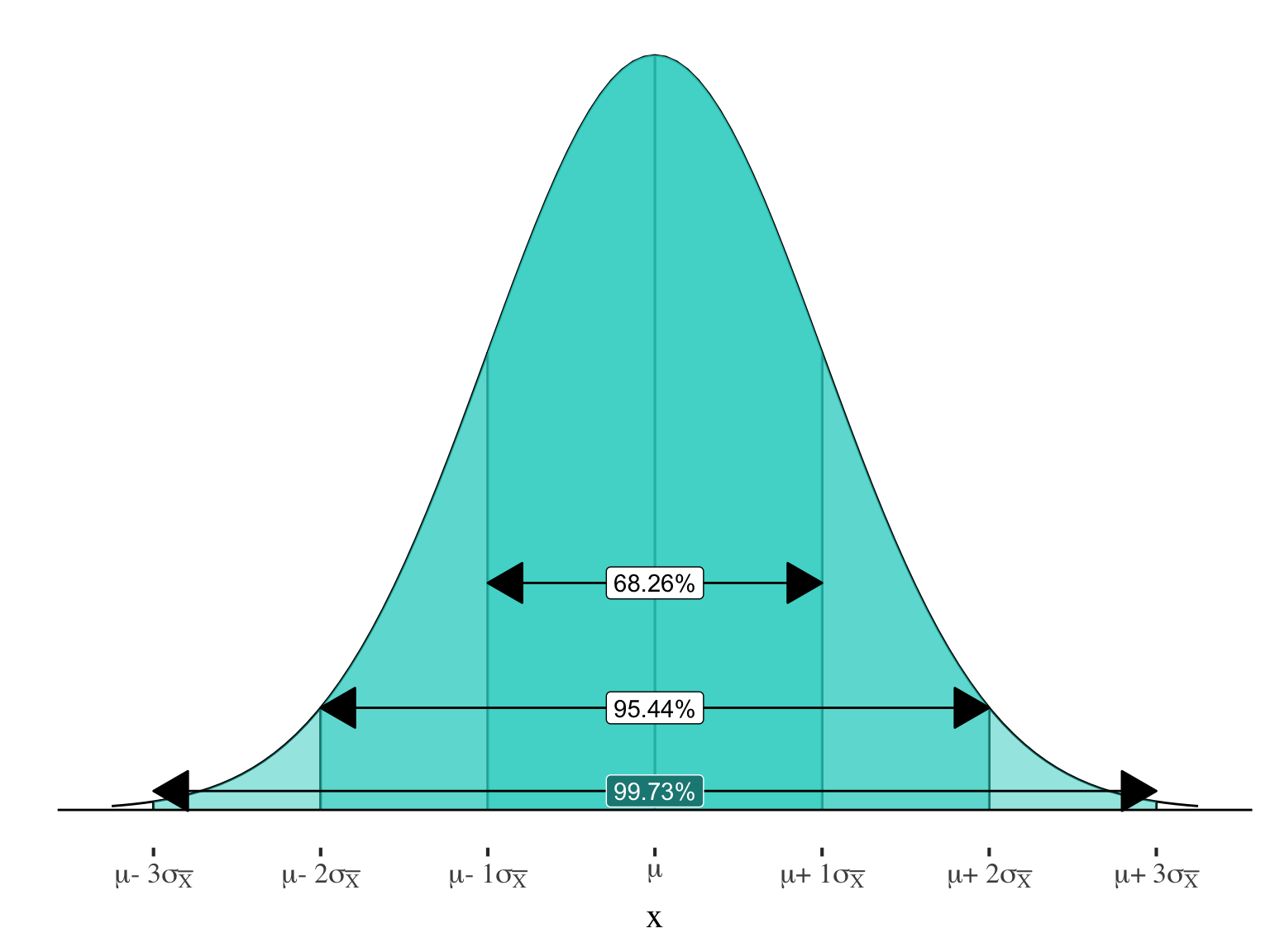
\(99.73\%\) of sample means will be within \(\pm3\) standard errors of the true population mean
How does this help us?
SAMPLING DISTRIBUTION of sample means

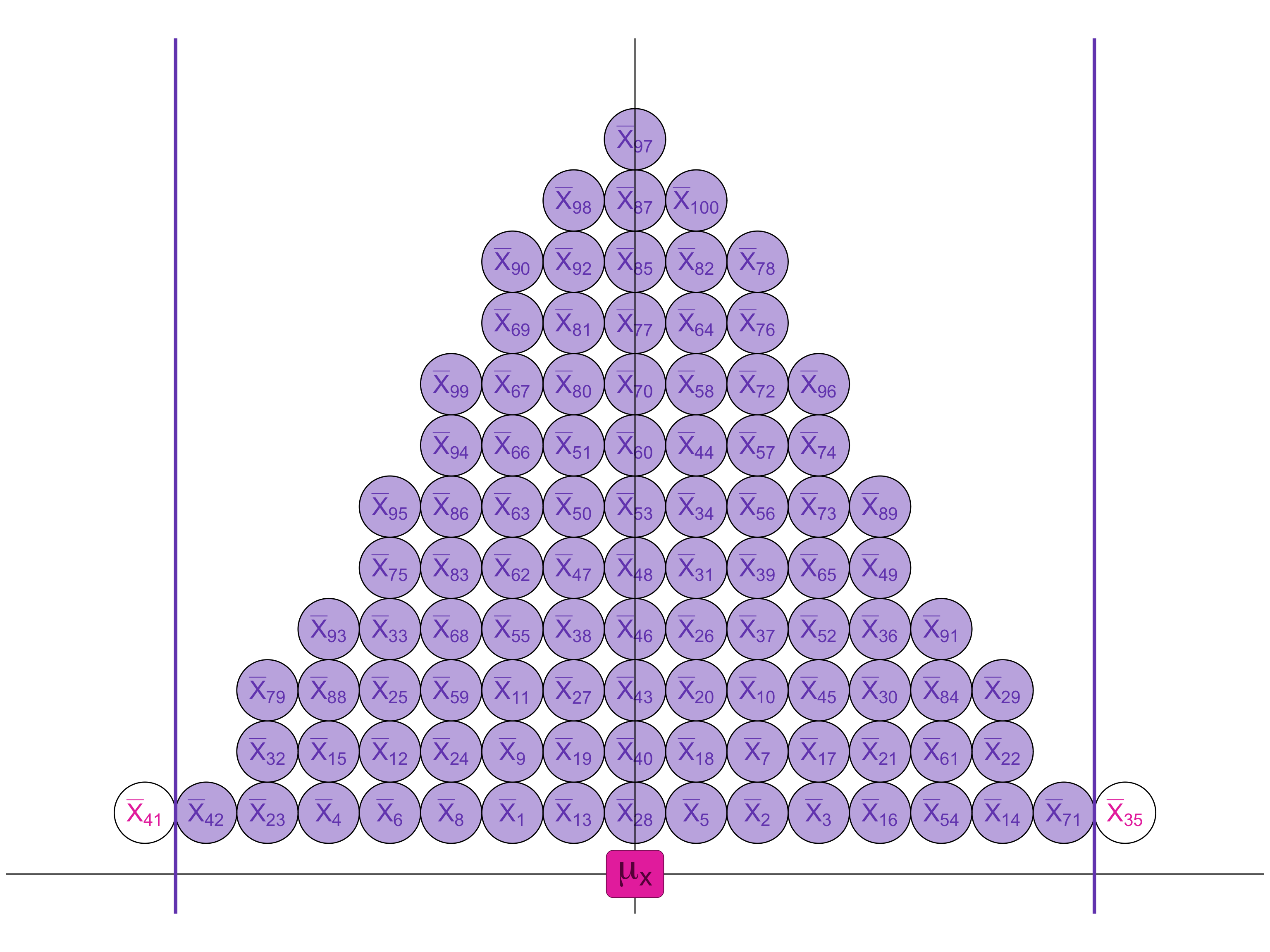
If, 95% of the samples are within 1.96 standard errors of the true population mean . . .
If, 95% of the samples are within 1.96 standard errors of the true population mean . . .
. . . then for 95 samples out of 100, we will find the true population mean if we look within 1.96 standard errors of the sample mean.
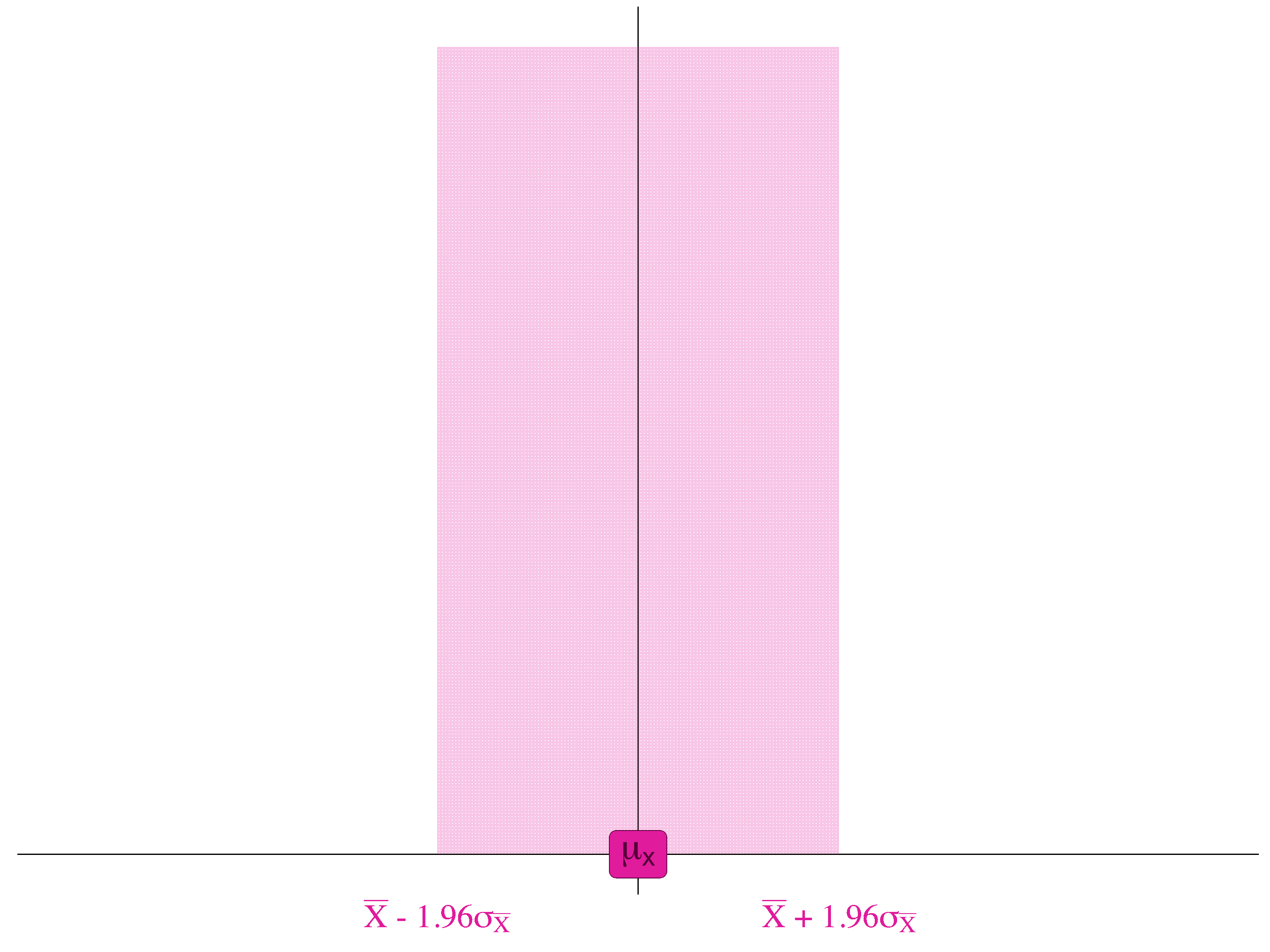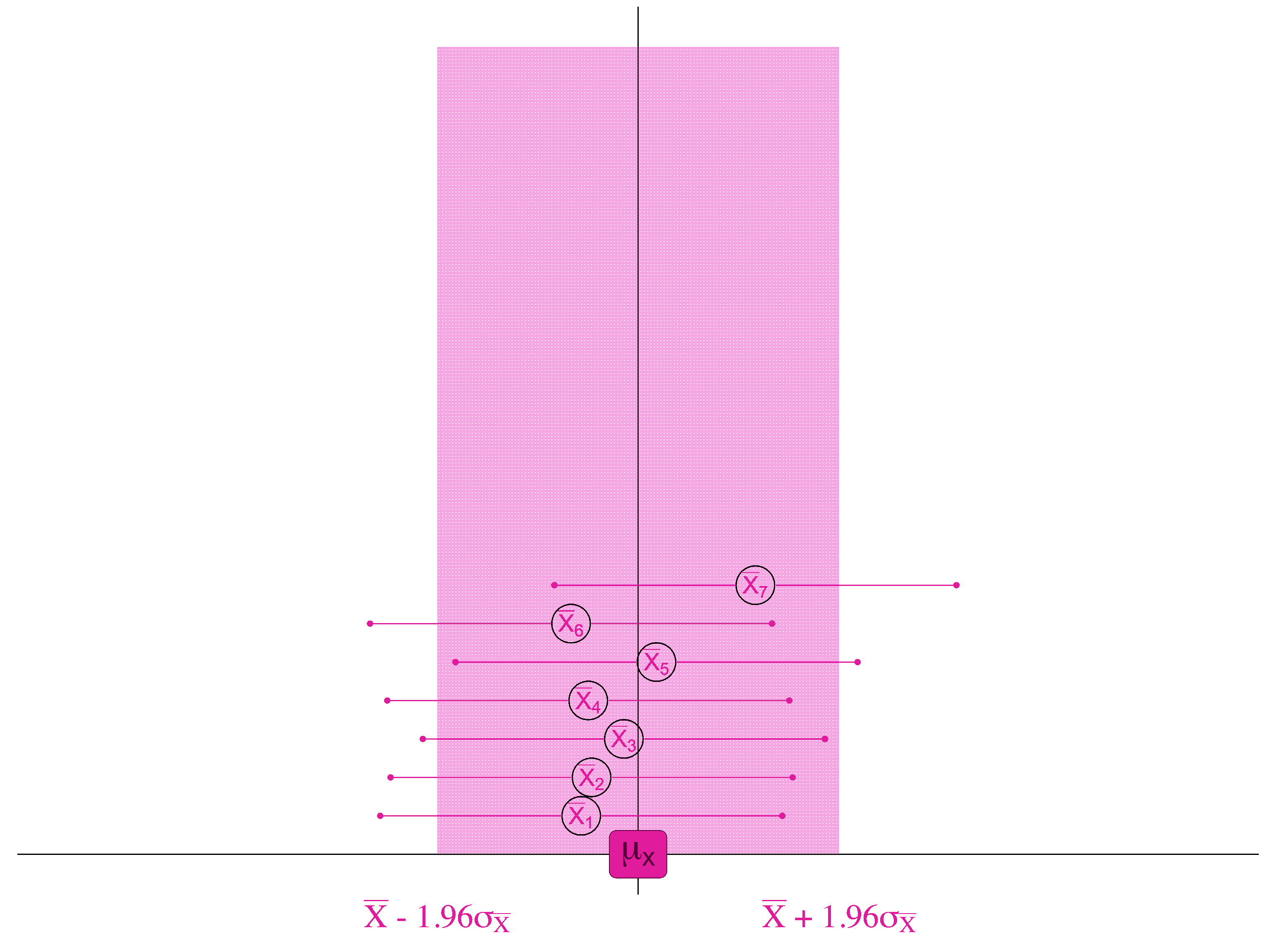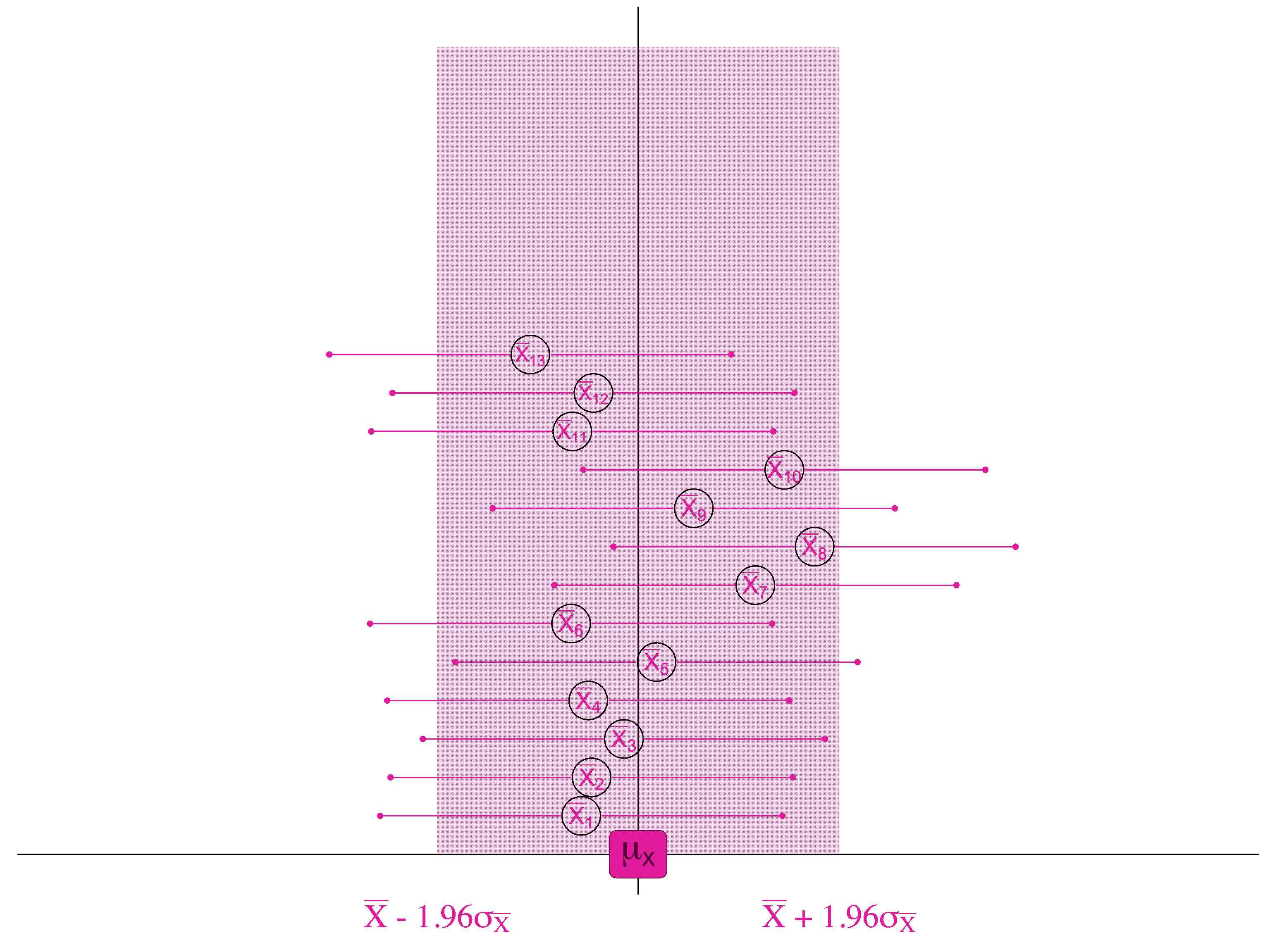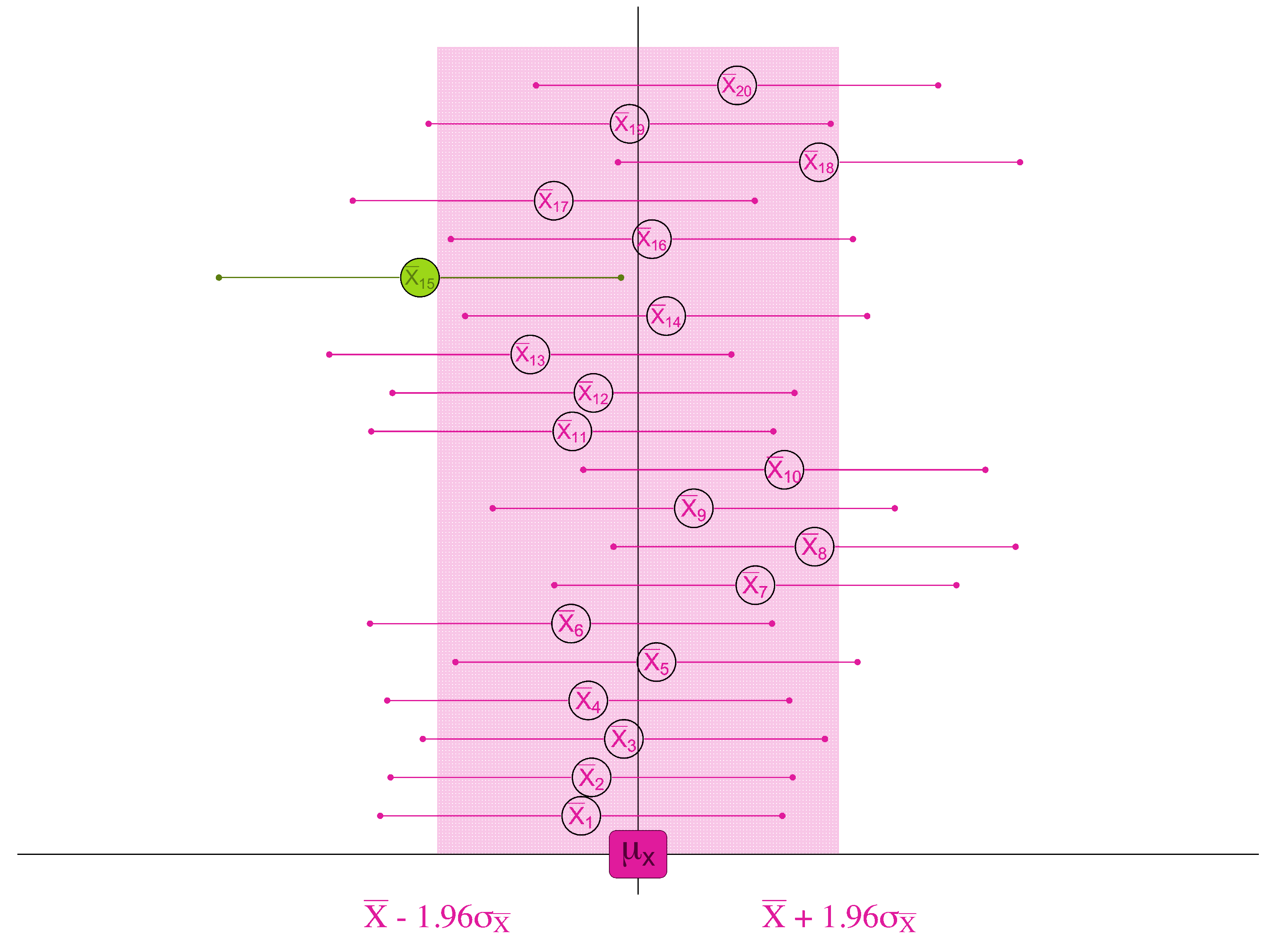
If, 95% of the samples are within 1.96 standard errors of the true population mean . . .
. . . then for 95 samples out of 100, we will find the true population mean if we look within 1.96 standard errors of the sample mean.
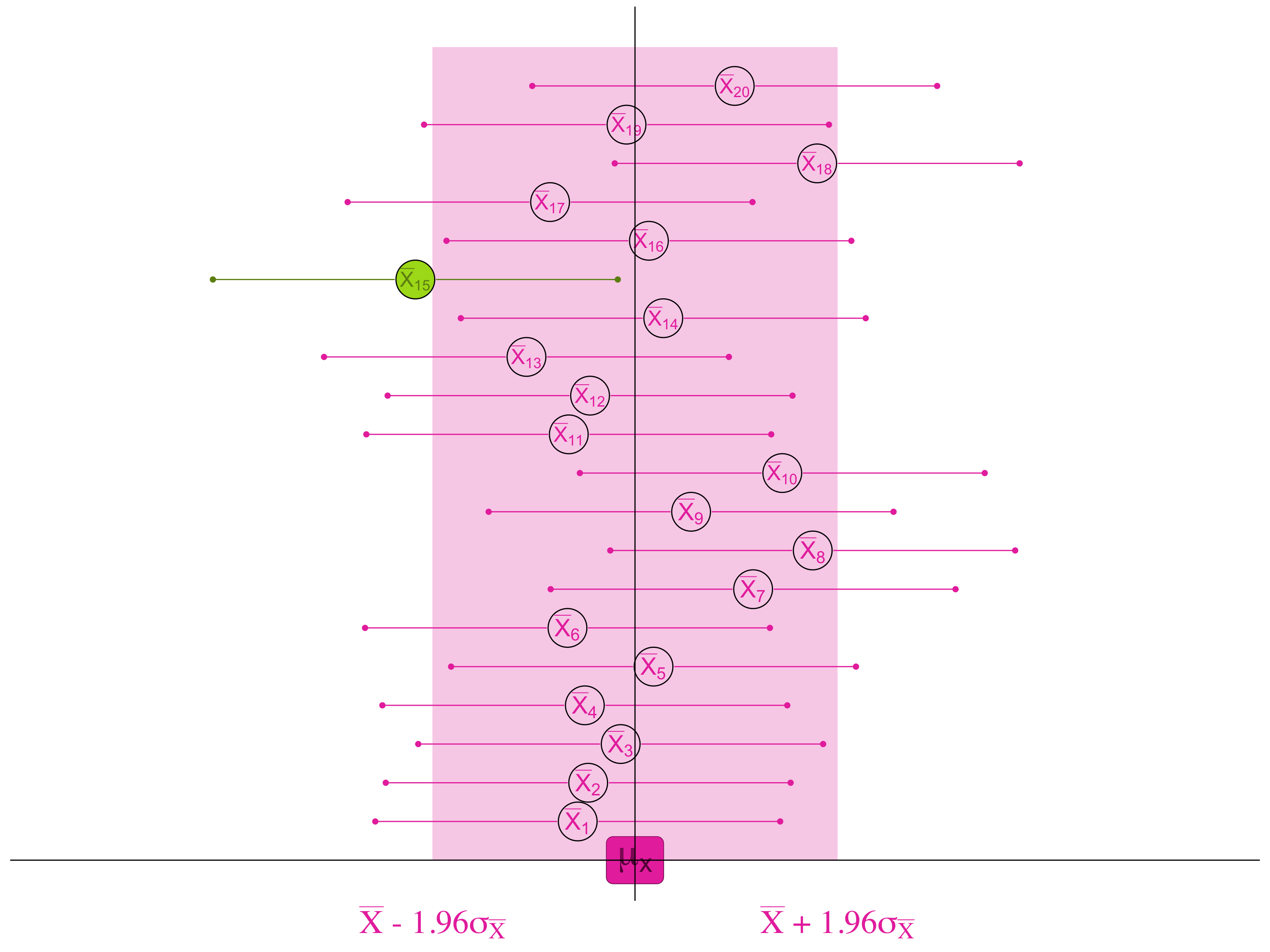
If, 95% of the samples are within 1.96 standard errors of the true population mean . . .
. . . then for 95 samples out of 100, we will find the true population mean if we look within 1.96 standard errors of the sample mean.