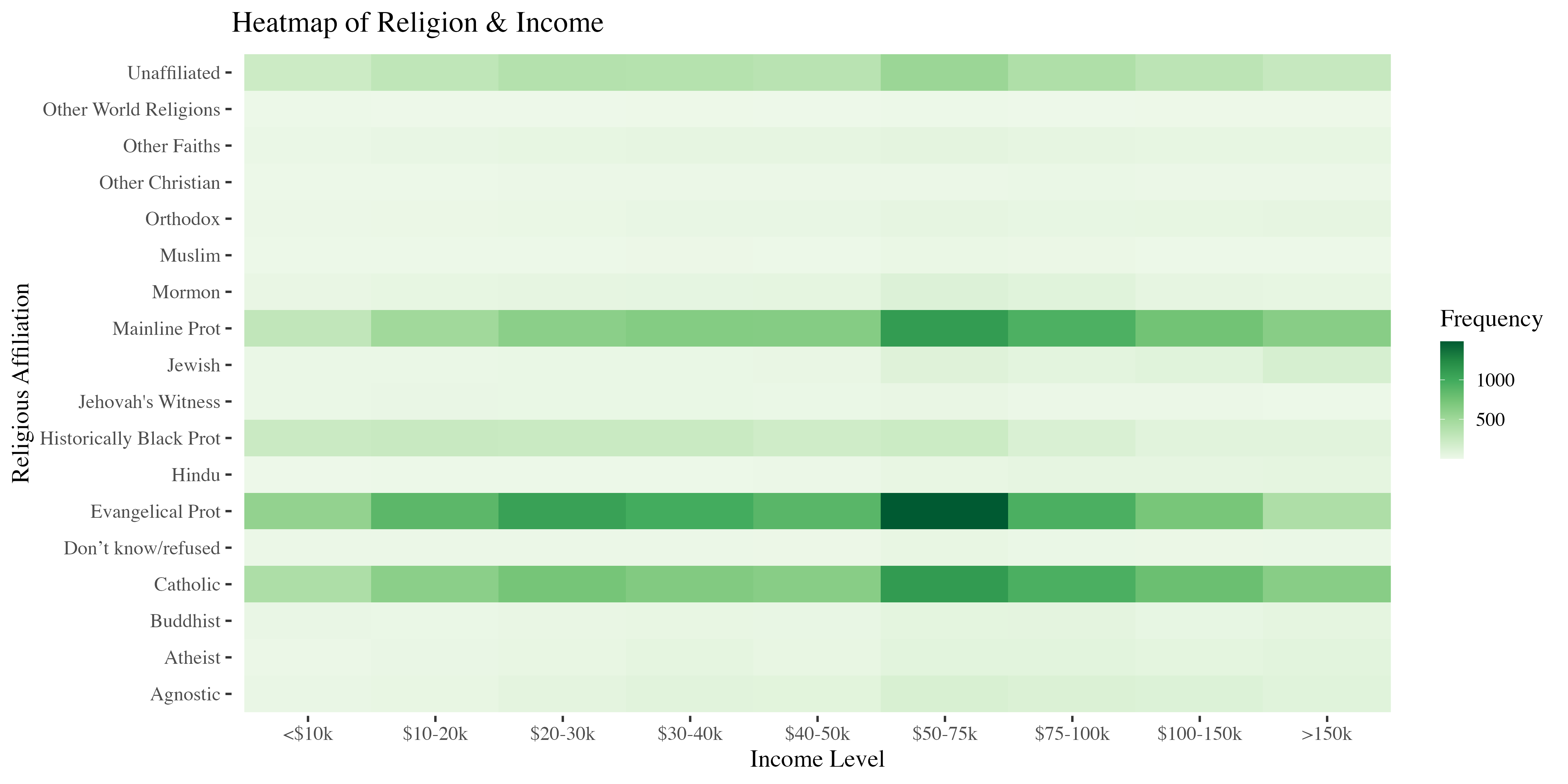
Importing, Exporting, & Cleaning Data
CS&SS 508 • Lecture 5
28 October 2025
Victoria Sass
Roadmap
Last time, we learned:
- Types of Data
- Logical Operators
- Using
dplyrto:- Subset data
- Modify data
- Summarize data
- Merge data
Today, we will cover:
- Importing and Exporting Data
- Tidying and Reshaping Data
- Types of Data
- Working with Factors
- Wrangling Date/Date-Time Data
Importing and Exporting Data
Data Packages
R has a big user base. If you are working with a popular data source, it will often have a devoted R package on CRAN or Github.
Examples:
-
WDI: World Development Indicators (World Bank) -
tidycensus: Census and American Community Survey -
quantmod: financial data from Yahoo, FRED, Google -
gssr: The General Social Survey Cumulative Data (1972-2021) -
psidR: Panel Study of Income Dynamics (basic & public datasets)
If you have an actual data file, you’ll have to import it yourself…
Delimited Text Files
Besides a package, it’s easiest when data is stored in a text file. The most commonly encountered delimited file is a .csv.
A comma-separated values (.csv) file looks like the following:
"Subject","Depression","Sex","Week","HamD","Imipramine"
101,"Non-endogenous","Second",0,26,NA
101,"Non-endogenous","Second",1,22,NA
101,"Non-endogenous","Second",2,18,4.04305
101,"Non-endogenous","Second",3,7,3.93183
101,"Non-endogenous","Second",4,4,4.33073
101,"Non-endogenous","Second",5,3,4.36945
103,"Non-endogenous","First",0,33,NA
103,"Non-endogenous","First",1,24,NA
103,"Non-endogenous","First",2,15,2.77259readr
R has some built-in functions for importing data, such as read.table() and read.csv().
The readr package provides similar functions, like read_csv(), that have slightly better features:
- Faster!
- Better defaults (e.g. doesn’t automatically convert characters to factors)
- A bit smarter about dates and times
- Loading progress bars for large files
readr is one of the core tidyverse packages so loading tidyverse will load it too:
readr Importing Example
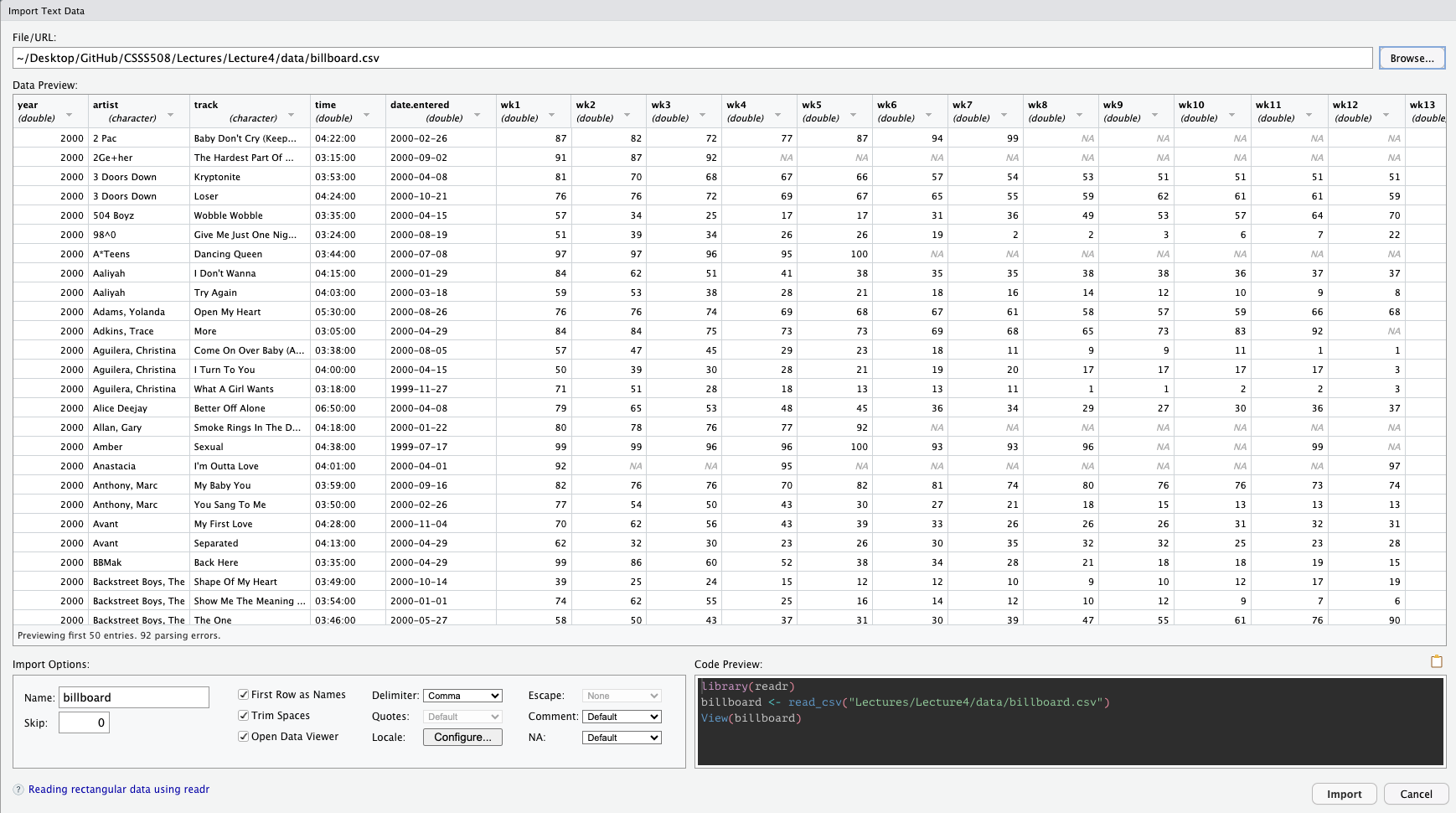
Let’s import some data about song ranks on the Billboard Hot 100 in 2000:
How do we know it loaded?
Let’s look at it!
> Rows: 317
> Columns: 80
> $ artist <chr> "2 Pac", "2Ge+her", "3 Doors Down", "3 Doors Down", "504 …
> $ track <chr> "Baby Don't Cry (Keep...", "The Hardest Part Of ...", "Kr…
> $ time <time> 04:22:00, 03:15:00, 03:53:00, 04:24:00, 03:35:00, 03:24:…
> $ date.entered <date> 2000-02-26, 2000-09-02, 2000-04-08, 2000-10-21, 2000-04-…
> $ wk1 <dbl> 87, 91, 81, 76, 57, 51, 97, 84, 59, 76, 84, 57, 50, 71, 7…
> $ wk2 <dbl> 82, 87, 70, 76, 34, 39, 97, 62, 53, 76, 84, 47, 39, 51, 6…
> $ wk3 <dbl> 72, 92, 68, 72, 25, 34, 96, 51, 38, 74, 75, 45, 30, 28, 5…
> $ wk4 <dbl> 77, NA, 67, 69, 17, 26, 95, 41, 28, 69, 73, 29, 28, 18, 4…
> $ wk5 <dbl> 87, NA, 66, 67, 17, 26, 100, 38, 21, 68, 73, 23, 21, 13, …
> $ wk6 <dbl> 94, NA, 57, 65, 31, 19, NA, 35, 18, 67, 69, 18, 19, 13, 3…
> $ wk7 <dbl> 99, NA, 54, 55, 36, 2, NA, 35, 16, 61, 68, 11, 20, 11, 34…
> $ wk8 <dbl> NA, NA, 53, 59, 49, 2, NA, 38, 14, 58, 65, 9, 17, 1, 29, …
> $ wk9 <dbl> NA, NA, 51, 62, 53, 3, NA, 38, 12, 57, 73, 9, 17, 1, 27, …
> $ wk10 <dbl> NA, NA, 51, 61, 57, 6, NA, 36, 10, 59, 83, 11, 17, 2, 30,…
> $ wk11 <dbl> NA, NA, 51, 61, 64, 7, NA, 37, 9, 66, 92, 1, 17, 2, 36, N…
> $ wk12 <dbl> NA, NA, 51, 59, 70, 22, NA, 37, 8, 68, NA, 1, 3, 3, 37, N…
> $ wk13 <dbl> NA, NA, 47, 61, 75, 29, NA, 38, 6, 61, NA, 1, 3, 3, 39, N…
> $ wk14 <dbl> NA, NA, 44, 66, 76, 36, NA, 49, 1, 67, NA, 1, 7, 4, 49, N…
> $ wk15 <dbl> NA, NA, 38, 72, 78, 47, NA, 61, 2, 59, NA, 4, 10, 12, 57,…
> $ wk16 <dbl> NA, NA, 28, 76, 85, 67, NA, 63, 2, 63, NA, 8, 17, 11, 63,…
> $ wk17 <dbl> NA, NA, 22, 75, 92, 66, NA, 62, 2, 67, NA, 12, 25, 13, 65…
> $ wk18 <dbl> NA, NA, 18, 67, 96, 84, NA, 67, 2, 71, NA, 22, 29, 15, 68…
> $ wk19 <dbl> NA, NA, 18, 73, NA, 93, NA, 83, 3, 79, NA, 23, 29, 18, 79…
> $ wk20 <dbl> NA, NA, 14, 70, NA, 94, NA, 86, 4, 89, NA, 43, 40, 20, 86…
> $ wk21 <dbl> NA, NA, 12, NA, NA, NA, NA, NA, 5, NA, NA, 44, 43, 30, NA…
> $ wk22 <dbl> NA, NA, 7, NA, NA, NA, NA, NA, 5, NA, NA, NA, 50, 40, NA,…
> $ wk23 <dbl> NA, NA, 6, NA, NA, NA, NA, NA, 6, NA, NA, NA, NA, 39, NA,…
> $ wk24 <dbl> NA, NA, 6, NA, NA, NA, NA, NA, 9, NA, NA, NA, NA, 44, NA,…
> $ wk25 <dbl> NA, NA, 6, NA, NA, NA, NA, NA, 13, NA, NA, NA, NA, NA, NA…
> $ wk26 <dbl> NA, NA, 5, NA, NA, NA, NA, NA, 14, NA, NA, NA, NA, NA, NA…
> $ wk27 <dbl> NA, NA, 5, NA, NA, NA, NA, NA, 16, NA, NA, NA, NA, NA, NA…
> $ wk28 <dbl> NA, NA, 4, NA, NA, NA, NA, NA, 23, NA, NA, NA, NA, NA, NA…
> $ wk29 <dbl> NA, NA, 4, NA, NA, NA, NA, NA, 22, NA, NA, NA, NA, NA, NA…
> $ wk30 <dbl> NA, NA, 4, NA, NA, NA, NA, NA, 33, NA, NA, NA, NA, NA, NA…
> $ wk31 <dbl> NA, NA, 4, NA, NA, NA, NA, NA, 36, NA, NA, NA, NA, NA, NA…
> $ wk32 <dbl> NA, NA, 3, NA, NA, NA, NA, NA, 43, NA, NA, NA, NA, NA, NA…
> $ wk33 <dbl> NA, NA, 3, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
> $ wk34 <dbl> NA, NA, 3, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
> $ wk35 <dbl> NA, NA, 4, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
> $ wk36 <dbl> NA, NA, 5, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
> $ wk37 <dbl> NA, NA, 5, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
> $ wk38 <dbl> NA, NA, 9, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
> $ wk39 <dbl> NA, NA, 9, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
> $ wk40 <dbl> NA, NA, 15, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
> $ wk41 <dbl> NA, NA, 14, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
> $ wk42 <dbl> NA, NA, 13, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
> $ wk43 <dbl> NA, NA, 14, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
> $ wk44 <dbl> NA, NA, 16, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
> $ wk45 <dbl> NA, NA, 17, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
> $ wk46 <dbl> NA, NA, 21, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
> $ wk47 <dbl> NA, NA, 22, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
> $ wk48 <dbl> NA, NA, 24, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
> $ wk49 <dbl> NA, NA, 28, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
> $ wk50 <dbl> NA, NA, 33, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
> $ wk51 <dbl> NA, NA, 42, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
> $ wk52 <dbl> NA, NA, 42, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
> $ wk53 <dbl> NA, NA, 49, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
> $ wk54 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
> $ wk55 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
> $ wk56 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
> $ wk57 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
> $ wk58 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
> $ wk59 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
> $ wk60 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
> $ wk61 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
> $ wk62 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
> $ wk63 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
> $ wk64 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
> $ wk65 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
> $ wk66 <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
> $ wk67 <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
> $ wk68 <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
> $ wk69 <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
> $ wk70 <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
> $ wk71 <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
> $ wk72 <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
> $ wk73 <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
> $ wk74 <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
> $ wk75 <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
> $ wk76 <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…Alternate Solution
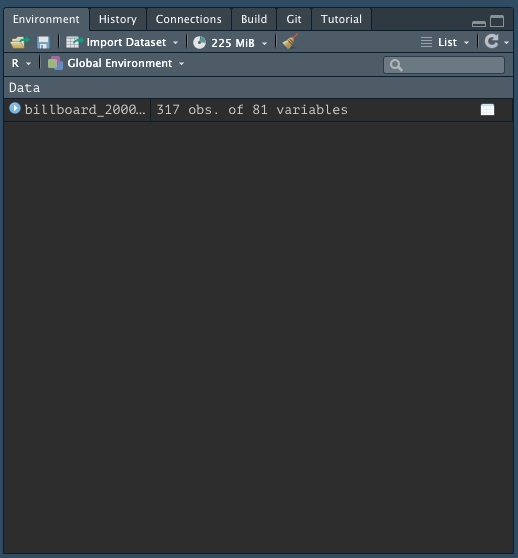
When you import data from an external file you’ll also see it in the Global Environment tab in the upper-right pane of RStudio:
You can also import the data manually!
In the upper right-hand pane of RStudio (make sure you’re in the Environment tab), select:
Import Dataset > From Text (readr) and browse to the file on your computer1.
Once you’ve imported the data, you can copy/paste the import code from the console into your file!!
This makes the process reproducible!
Manual Data Import
Specifying NAs
NAs are technically logical (boolean) variables that indicate a missing value.
Skipping lines
Depending on how the data were input, there may be several lines that precede the beginning of the data table you’re interested in importing. You can skip these lines of metadata with the skip argument:
Variable names
read_csv will automatically take the first row as column names. If you want to rename them you can save yourself some time recoding later on if you specify your preferred variable names upfront with the col_names argument.
It takes a character vector to be used as column names (in their order of appearance).
billboard_renamed <- read_csv(
file = "data/billboard_top100.csv",
col_names = c("year", "artist", "track", "time", "date_entered",
paste("wk", 1:76, sep = "_"))
)
billboard_renamed |> names() |> head(10)- 1
-
paste“pastes” together the first argument to the second argument (separated by whatever is specified in thesepargument) as character strings. Since the first argument here is a singular value, it is repeated for the entire length of the vector in the second argument. The first several values ofpaste("wk", 1:76, sep = "_")are: wk_1, wk_2, wk_3, wk_4, wk_5, wk_6 - 2
-
nameshere returns the column names of our data frame.
> [1] "year" "artist" "track" "time" "date_entered"
> [6] "wk_1" "wk_2" "wk_3" "wk_4" "wk_5"Snake Case
If you simply want to change your variables to snake case (all lower case; words separated by _), you can use the function clean_names() from the janitor package which replaces other punctuation separators with _.
billboard_renamed <- billboard_2000_raw |>
janitor::clean_names(numerals = "right")
billboard_renamed |> names() |> head(10)- 1
- Create new object for renamed data
- 2
-
Run
install.packages("janitor")in the console first. You can then call a function fromjanitorwithout loading the entire package by specifying its package name followed by::before the function name.;
Thenumeralsargument specifies if you additionally want to put a separator before a number.
> [1] "artist" "track" "time" "date_entered" "wk_1"
> [6] "wk_2" "wk_3" "wk_4" "wk_5" "wk_6"Other Data File Types with readr
The other functions in readr employ a similar approach to read_csv so the trick is just knowing which to use for what data type.
-
read_csv2is separated by semicolons (instead of commas) -
read_tsvis separated by tabs -
read_delimguesses the delimiter -
read_fwfreads in fixed-width-files -
read_tableis a variation offwfwhere columns are separated by white space -
read_logreads in Apache-style log files
Other Packages to Read in Data
There are a range of other ways, besides delimited files, that data are stored.
The following packages are part of the extended tidyverse and therefore operate with similar syntax and logic as readr.
Other Packages to Read in Data
There are a range of other ways, besides delimited files, that data are stored.
The following packages are part of the extended tidyverse and therefore operate with similar syntax and logic as readr.

- For Excel files (
.xlsor.xlsx), use packagereadxl1
Other Packages to Read in Data
There are a range of other ways, besides delimited files, that data are stored.
The following packages are part of the extended tidyverse and therefore operate with similar syntax and logic as readr.

- For Excel files (
.xlsor.xlsx), use packagereadxl1 - For Google Docs Spreadsheets, use package
googlesheets42
Other Packages to Read in Data
There are a range of other ways, besides delimited files, that data are stored.
The following packages are part of the extended tidyverse and therefore operate with similar syntax and logic as readr.

- For Excel files (
.xlsor.xlsx), use packagereadxl1 - For Google Docs Spreadsheets, use package
googlesheets42 - For Stata, SPSS, and SAS files, use package
haven3
How does readr parse different data types?
For each column in a data frame, readr functions pull the first 1000 rows and checks:
flowchart LR
id1((Variable))==>A(["1: Does it contain only F, T, FALSE, <br/> TRUE, or NA (ignoring case)?"])==>id2{{Logical}}
id1((Variable))==>B(["2: Does it contain only numbers <br/> (e.g., 1, -4.5, 5e6, Inf?)"])==>id3{{Number}}
id1((Variable))==>C(["3: Does it match the <br/> ISO8601 standard?"])==>id4{{Date/Date-time}}
id1((Variable))==>D(["4: None of the above"])==>id5{{String}}
style id1 fill:#1e4655,color:#c7cdac,stroke:#c7cdac
style id2 fill:#c7cdac,color:#1e4655,stroke:#1e4655
style id3 fill:#c7cdac,color:#1e4655,stroke:#1e4655
style id4 fill:#c7cdac,color:#1e4655,stroke:#1e4655
style id5 fill:#c7cdac,color:#1e4655,stroke:#1e4655
style A fill:#FFFFFF,color:#000000,stroke:#000000
style B fill:#FFFFFF,color:#000000,stroke:#000000
style C fill:#FFFFFF,color:#000000,stroke:#000000
style D fill:#FFFFFF,color:#000000,stroke:#000000
How does readr parse different data types?
For each column in a data frame, readr functions pull the first 1000 rows and checks:
flowchart LR
id1((Variable))==>A(["1: Does it contain only F, T, FALSE, <br/> TRUE, or NA (ignoring case)?"])==>id2{{Logical}}
id1((Variable))==>B(["2: Does it contain only numbers <br/> (e.g., 1, -4.5, 5e6, Inf?)"])==>id3{{Number}}
id1((Variable))==>C(["3: Does it match the <br/> ISO8601 standard?"])==>id4{{Date/Date-time}}
id1((Variable))==>D(["4: None of the above"])==>id5{{String}}
style id1 fill:#1e4655,color:#c7cdac,stroke:#c7cdac
style id2 fill:#1e4655,color:#c7cdac,stroke:#c7cdac
style id3 fill:#c7cdac,color:#1e4655,stroke:#1e4655
style id4 fill:#c7cdac,color:#1e4655,stroke:#1e4655
style id5 fill:#c7cdac,color:#1e4655,stroke:#1e4655
style A fill:#ffa07a,color:#000000,stroke:#000000
style B fill:#FFFFFF,color:#000000,stroke:#000000
style C fill:#FFFFFF,color:#000000,stroke:#000000
style D fill:#FFFFFF,color:#000000,stroke:#000000
How does readr parse different data types?
For each column in a data frame, readr functions pull the first 1000 rows and checks:
flowchart LR
id1((Variable))==>A(["1: Does it contain only F, T, FALSE, <br/> TRUE, or NA (ignoring case)?"])==>id2{{Logical}}
id1((Variable))==>B(["2: Does it contain only numbers <br/> (e.g., 1, -4.5, 5e6, Inf?)"])==>id3{{Number}}
id1((Variable))==>C(["3: Does it match the <br/> ISO8601 standard?"])==>id4{{Date/Date-time}}
id1((Variable))==>D(["4: None of the above"])==>id5{{String}}
style id1 fill:#1e4655,color:#c7cdac,stroke:#c7cdac
style id2 fill:#c7cdac,color:#1e4655,stroke:#1e4655
style id3 fill:#1e4655,color:#c7cdac,stroke:#c7cdac
style id4 fill:#c7cdac,color:#1e4655,stroke:#1e4655
style id5 fill:#c7cdac,color:#1e4655,stroke:#1e4655
style A fill:#FFFFFF,color:#000000,stroke:#000000
style B fill:#ffa07a,color:#000000,stroke:#000000
style C fill:#FFFFFF,color:#000000,stroke:#000000
style D fill:#FFFFFF,color:#000000,stroke:#000000
How does readr parse different data types?
For each column in a data frame, readr functions pull the first 1000 rows and checks:
flowchart LR
id1((Variable))==>A(["1: Does it contain only F, T, FALSE, <br/> TRUE, or NA (ignoring case)?"])==>id2{{Logical}}
id1((Variable))==>B(["2: Does it contain only numbers <br/> (e.g., 1, -4.5, 5e6, Inf?)"])==>id3{{Number}}
id1((Variable))==>C(["3: Does it match the <br/> ISO8601 standard?"])==>id4{{Date/Date-time}}
id1((Variable))==>D(["4: None of the above"])==>id5{{String}}
style id1 fill:#1e4655,color:#c7cdac,stroke:#c7cdac
style id2 fill:#c7cdac,color:#1e4655,stroke:#1e4655
style id3 fill:#c7cdac,color:#1e4655,stroke:#1e4655
style id4 fill:#1e4655,color:#c7cdac,stroke:#c7cdac
style id5 fill:#c7cdac,color:#1e4655,stroke:#1e4655
style A fill:#FFFFFF,color:#000000,stroke:#000000
style B fill:#FFFFFF,color:#000000,stroke:#000000
style C fill:#ffa07a,color:#000000,stroke:#000000
style D fill:#FFFFFF,color:#000000,stroke:#000000
How does readr parse different data types?
For each column in a data frame, readr functions pull the first 1000 rows and checks:
flowchart LR
id1((Variable))==>A(["1: Does it contain only F, T, FALSE, <br/> TRUE, or NA (ignoring case)?"])==>id2{{Logical}}
id1((Variable))==>B(["2: Does it contain only numbers <br/> (e.g., 1, -4.5, 5e6, Inf?)"])==>id3{{Number}}
id1((Variable))==>C(["3: Does it match the <br/> ISO8601 standard?"])==>id4{{Date/Date-time}}
id1((Variable))==>D(["4: None of the above"])==>id5{{String}}
style id1 fill:#1e4655,color:#c7cdac,stroke:#c7cdac
style id2 fill:#c7cdac,color:#1e4655,stroke:#1e4655
style id3 fill:#c7cdac,color:#1e4655,stroke:#1e4655
style id4 fill:#c7cdac,color:#1e4655,stroke:#1e4655
style id5 fill:#1e4655,color:#c7cdac,stroke:#c7cdac
style A fill:#FFFFFF,color:#000000,stroke:#000000
style B fill:#FFFFFF,color:#000000,stroke:#000000
style C fill:#FFFFFF,color:#000000,stroke:#000000
style D fill:#ffa07a,color:#000000,stroke:#000000
Most Common Issue with Reading in Data
The most common problem that occurs when reading in data is having mixed data. Most often, given the heuristic provided in the last slide, readr will parse a variable as a character string to preserve whatever it contains.
Let’s actually look at how the billboard data was read in:
> Rows: 317
> Columns: 80
> $ artist <chr> "2 Pac", "2Ge+her", "3 Doors Down", "3 Doors Down", "504 …
> $ track <chr> "Baby Don't Cry (Keep...", "The Hardest Part Of ...", "Kr…
> $ time <time> 04:22:00, 03:15:00, 03:53:00, 04:24:00, 03:35:00, 03:24:…
> $ date.entered <date> 2000-02-26, 2000-09-02, 2000-04-08, 2000-10-21, 2000-04-…
> $ wk1 <dbl> 87, 91, 81, 76, 57, 51, 97, 84, 59, 76, 84, 57, 50, 71, 7…
> $ wk2 <dbl> 82, 87, 70, 76, 34, 39, 97, 62, 53, 76, 84, 47, 39, 51, 6…
> $ wk3 <dbl> 72, 92, 68, 72, 25, 34, 96, 51, 38, 74, 75, 45, 30, 28, 5…
> $ wk4 <dbl> 77, NA, 67, 69, 17, 26, 95, 41, 28, 69, 73, 29, 28, 18, 4…
> $ wk5 <dbl> 87, NA, 66, 67, 17, 26, 100, 38, 21, 68, 73, 23, 21, 13, …
> $ wk6 <dbl> 94, NA, 57, 65, 31, 19, NA, 35, 18, 67, 69, 18, 19, 13, 3…
> $ wk7 <dbl> 99, NA, 54, 55, 36, 2, NA, 35, 16, 61, 68, 11, 20, 11, 34…
> $ wk8 <dbl> NA, NA, 53, 59, 49, 2, NA, 38, 14, 58, 65, 9, 17, 1, 29, …
> $ wk9 <dbl> NA, NA, 51, 62, 53, 3, NA, 38, 12, 57, 73, 9, 17, 1, 27, …
> $ wk10 <dbl> NA, NA, 51, 61, 57, 6, NA, 36, 10, 59, 83, 11, 17, 2, 30,…
> $ wk11 <dbl> NA, NA, 51, 61, 64, 7, NA, 37, 9, 66, 92, 1, 17, 2, 36, N…
> $ wk12 <dbl> NA, NA, 51, 59, 70, 22, NA, 37, 8, 68, NA, 1, 3, 3, 37, N…
> $ wk13 <dbl> NA, NA, 47, 61, 75, 29, NA, 38, 6, 61, NA, 1, 3, 3, 39, N…
> $ wk14 <dbl> NA, NA, 44, 66, 76, 36, NA, 49, 1, 67, NA, 1, 7, 4, 49, N…
> $ wk15 <dbl> NA, NA, 38, 72, 78, 47, NA, 61, 2, 59, NA, 4, 10, 12, 57,…
> $ wk16 <dbl> NA, NA, 28, 76, 85, 67, NA, 63, 2, 63, NA, 8, 17, 11, 63,…
> $ wk17 <dbl> NA, NA, 22, 75, 92, 66, NA, 62, 2, 67, NA, 12, 25, 13, 65…
> $ wk18 <dbl> NA, NA, 18, 67, 96, 84, NA, 67, 2, 71, NA, 22, 29, 15, 68…
> $ wk19 <dbl> NA, NA, 18, 73, NA, 93, NA, 83, 3, 79, NA, 23, 29, 18, 79…
> $ wk20 <dbl> NA, NA, 14, 70, NA, 94, NA, 86, 4, 89, NA, 43, 40, 20, 86…
> $ wk21 <dbl> NA, NA, 12, NA, NA, NA, NA, NA, 5, NA, NA, 44, 43, 30, NA…
> $ wk22 <dbl> NA, NA, 7, NA, NA, NA, NA, NA, 5, NA, NA, NA, 50, 40, NA,…
> $ wk23 <dbl> NA, NA, 6, NA, NA, NA, NA, NA, 6, NA, NA, NA, NA, 39, NA,…
> $ wk24 <dbl> NA, NA, 6, NA, NA, NA, NA, NA, 9, NA, NA, NA, NA, 44, NA,…
> $ wk25 <dbl> NA, NA, 6, NA, NA, NA, NA, NA, 13, NA, NA, NA, NA, NA, NA…
> $ wk26 <dbl> NA, NA, 5, NA, NA, NA, NA, NA, 14, NA, NA, NA, NA, NA, NA…
> $ wk27 <dbl> NA, NA, 5, NA, NA, NA, NA, NA, 16, NA, NA, NA, NA, NA, NA…
> $ wk28 <dbl> NA, NA, 4, NA, NA, NA, NA, NA, 23, NA, NA, NA, NA, NA, NA…
> $ wk29 <dbl> NA, NA, 4, NA, NA, NA, NA, NA, 22, NA, NA, NA, NA, NA, NA…
> $ wk30 <dbl> NA, NA, 4, NA, NA, NA, NA, NA, 33, NA, NA, NA, NA, NA, NA…
> $ wk31 <dbl> NA, NA, 4, NA, NA, NA, NA, NA, 36, NA, NA, NA, NA, NA, NA…
> $ wk32 <dbl> NA, NA, 3, NA, NA, NA, NA, NA, 43, NA, NA, NA, NA, NA, NA…
> $ wk33 <dbl> NA, NA, 3, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
> $ wk34 <dbl> NA, NA, 3, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
> $ wk35 <dbl> NA, NA, 4, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
> $ wk36 <dbl> NA, NA, 5, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
> $ wk37 <dbl> NA, NA, 5, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
> $ wk38 <dbl> NA, NA, 9, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
> $ wk39 <dbl> NA, NA, 9, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
> $ wk40 <dbl> NA, NA, 15, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
> $ wk41 <dbl> NA, NA, 14, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
> $ wk42 <dbl> NA, NA, 13, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
> $ wk43 <dbl> NA, NA, 14, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
> $ wk44 <dbl> NA, NA, 16, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
> $ wk45 <dbl> NA, NA, 17, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
> $ wk46 <dbl> NA, NA, 21, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
> $ wk47 <dbl> NA, NA, 22, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
> $ wk48 <dbl> NA, NA, 24, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
> $ wk49 <dbl> NA, NA, 28, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
> $ wk50 <dbl> NA, NA, 33, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
> $ wk51 <dbl> NA, NA, 42, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
> $ wk52 <dbl> NA, NA, 42, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
> $ wk53 <dbl> NA, NA, 49, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
> $ wk54 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
> $ wk55 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
> $ wk56 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
> $ wk57 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
> $ wk58 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
> $ wk59 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
> $ wk60 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
> $ wk61 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
> $ wk62 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
> $ wk63 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
> $ wk64 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
> $ wk65 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
> $ wk66 <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
> $ wk67 <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
> $ wk68 <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
> $ wk69 <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
> $ wk70 <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
> $ wk71 <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
> $ wk72 <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
> $ wk73 <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
> $ wk74 <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
> $ wk75 <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
> $ wk76 <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…What Went Wrong?
Since readr uses the values in the first 1000 rows to guess the type of the column (logical, numeric, date/date-time, character), if the first 1000 rows don’t have any data, they will be coded as logical variables.
There are not many songs in the data that charted for 60+ weeks—and none in the first 1000 that charted for 66+ weeks!
NA is logical?
> [1] "logical"> [1] "numeric"- 2
-
as.Dateturns a character string of dates into an official date class in BaseR. If we had an accompanying time stamp we would need to useas.POSIXctwhich turns a character string of dates and times into an official date-time class in BaseR.
> [1] "Date"> [1] "character"> [1] "logical"Column types
Since the wk* variables should all be read in as integers, we can specify this explicitly with the col_types argument.
# Create character string of shortcode column types
bb_types <- paste(c("cctD", rep("i", 76)), collapse="")
bb_types - 1
-
You can short-code column types with
c= character,t= time,D= date,i= integer.
Thecollapseargument collapses the first two arguments into one complete character string.
> [1] "cctDiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiii"billboard_2000_raw <- read_csv(file = "data/billboard_top100.csv",
col_types = bb_types)
billboard_2000_raw |> select(wk66:wk76)- 2
- When we re-read in the data, this string now specifies the data type for each column of our data frame. Visit this reference page to see all available column types and their short codes.
- 3
- Checking the previously incorrectly parsed variables
> # A tibble: 317 × 11
> wk66 wk67 wk68 wk69 wk70 wk71 wk72 wk73 wk74 wk75 wk76
> <int> <int> <int> <int> <int> <int> <int> <int> <int> <int> <int>
> 1 NA NA NA NA NA NA NA NA NA NA NA
> 2 NA NA NA NA NA NA NA NA NA NA NA
> 3 NA NA NA NA NA NA NA NA NA NA NA
> 4 NA NA NA NA NA NA NA NA NA NA NA
> 5 NA NA NA NA NA NA NA NA NA NA NA
> 6 NA NA NA NA NA NA NA NA NA NA NA
> 7 NA NA NA NA NA NA NA NA NA NA NA
> 8 NA NA NA NA NA NA NA NA NA NA NA
> 9 NA NA NA NA NA NA NA NA NA NA NA
> 10 NA NA NA NA NA NA NA NA NA NA NA
> # ℹ 307 more rowsColumn types
To specify a default column type you can use .default like so:
Another useful helper is cols_only() for when you only want to read in a subset of all available variables.
In summary, the col_types argument gives you greater control over how your data are read in and can save you recoding time down the road and/or point out where your data are behaving differently than you expect.
Reading in Multiple Files
If your data are split across multiple files you can read them in all at once by specifying the id argument.
> # A tibble: 19 × 6
> file month year brand item n
> <chr> <chr> <dbl> <dbl> <dbl> <dbl>
> 1 data/01_sales.csv January 2019 1 1234 3
> 2 data/01_sales.csv January 2019 1 8721 9
> 3 data/01_sales.csv January 2019 1 1822 2
> 4 data/01_sales.csv January 2019 2 3333 1
> 5 data/01_sales.csv January 2019 2 2156 9
> 6 data/01_sales.csv January 2019 2 3987 6
> 7 data/01_sales.csv January 2019 2 3827 6
> 8 data/02_sales.csv February 2019 1 1234 8
> 9 data/02_sales.csv February 2019 1 8721 2
> 10 data/02_sales.csv February 2019 1 1822 3
> 11 data/02_sales.csv February 2019 2 3333 1
> 12 data/02_sales.csv February 2019 2 2156 3
> 13 data/02_sales.csv February 2019 2 3987 6
> 14 data/03_sales.csv March 2019 1 1234 3
> 15 data/03_sales.csv March 2019 1 3627 1
> 16 data/03_sales.csv March 2019 1 8820 3
> 17 data/03_sales.csv March 2019 2 7253 1
> 18 data/03_sales.csv March 2019 2 8766 3
> 19 data/03_sales.csv March 2019 2 8288 6Reading in Multiple Files
If you have too many files to reasonably type out all their names you can also use the base r function list.files to list the files for you.
# Create list of files with pattern-matching
sales_files <- list.files("data",
pattern = "sales\\.csv$",
full.names = TRUE)
sales_files- 1
- We will discuss pattern-matching more in a couple of weeks; if all your data was in one folder without anything else in it, you wouldn’t need to specify this argument. Sometimes, however, you may be searching through larger directories that you did not organize and that’s when pattern-matching is really powerful.
> [1] "data/01_sales.csv" "data/02_sales.csv" "data/03_sales.csv"Data Entry
Sometimes you’ll need to create a data set in your code. You can do this two ways:
Tibbles lay out the data by columns (i.e. a dataframe transposed).
> # A tibble: 3 × 3
> x y z
> <dbl> <chr> <dbl>
> 1 1 h 0.08
> 2 2 m 0.83
> 3 5 g 0.6Writing Delimited Files
Getting data out of R into a delimited file is very similar to getting it into R:
This saved the data we pulled off the web in a file called billboard_data.csv in the data folder of my working directory.
However, saving data in this way will not preserve R data types since delimited files code everything as a character string.
To save R objects and all associated metadata you have two options:
- Used for single objects, doesn’t save original the object name
- Save:
write_rds(old_object_name, "path.Rds") - Load:
new_object_name <- read_rds("path.Rds")
- Used for saving multiple files where the original object names are preserved
- Save:
save(object1, object2, ... , file = "path.Rdata") - Load:
load("path.Rdata")without assignment operator
Writing Other File-Types
-
write_xlsx()writes to an xlsx file

-
sheet_write()orwrite_sheet()(over)writes new data into a Sheet -
gs4_create()creates a new Sheet -
sheet_append()appends rows to a sheet -
range_write()(over)writes new data into a range -
range_flood()floods a range of cells - `
range_clear()clears a range of cells
-
write_dta()writes Stata DTA files -
write_sav()writes SPSS files -
write_xpt()writes SAS transport files
Lab
Importing & Tidying Data
- Go to the Lecture 5 Homepage and click on the link
Religion & Incomeunder the Data section. - Click File > Save to download this data to the same folder where your source document1 will be saved for this lab.
- Read in your data using the appropriate function from
readr.
Tidying and Reshaping Data
Initial Spot Checks
First things to check after loading new data:
- Did all the rows/columns from the original file make it in?
- Are the column names in good shape?
- Use
names()to check; re-read in usingcol_names()or fix withrename()
- Use
- Are there “decorative” blank rows or columns to remove?
-
filter()orselect()out those rows/columns
-
- How are missing values represented:
NA," "(blank),.(period),999?- Read in the data again specifying
NAs with thenaargument
- Read in the data again specifying
- Are there character data (e.g. ZIP codes with leading zeroes) being incorrectly represented as numeric or vice versa?
- Read in the data again specifying desired
col_types
- Read in the data again specifying desired
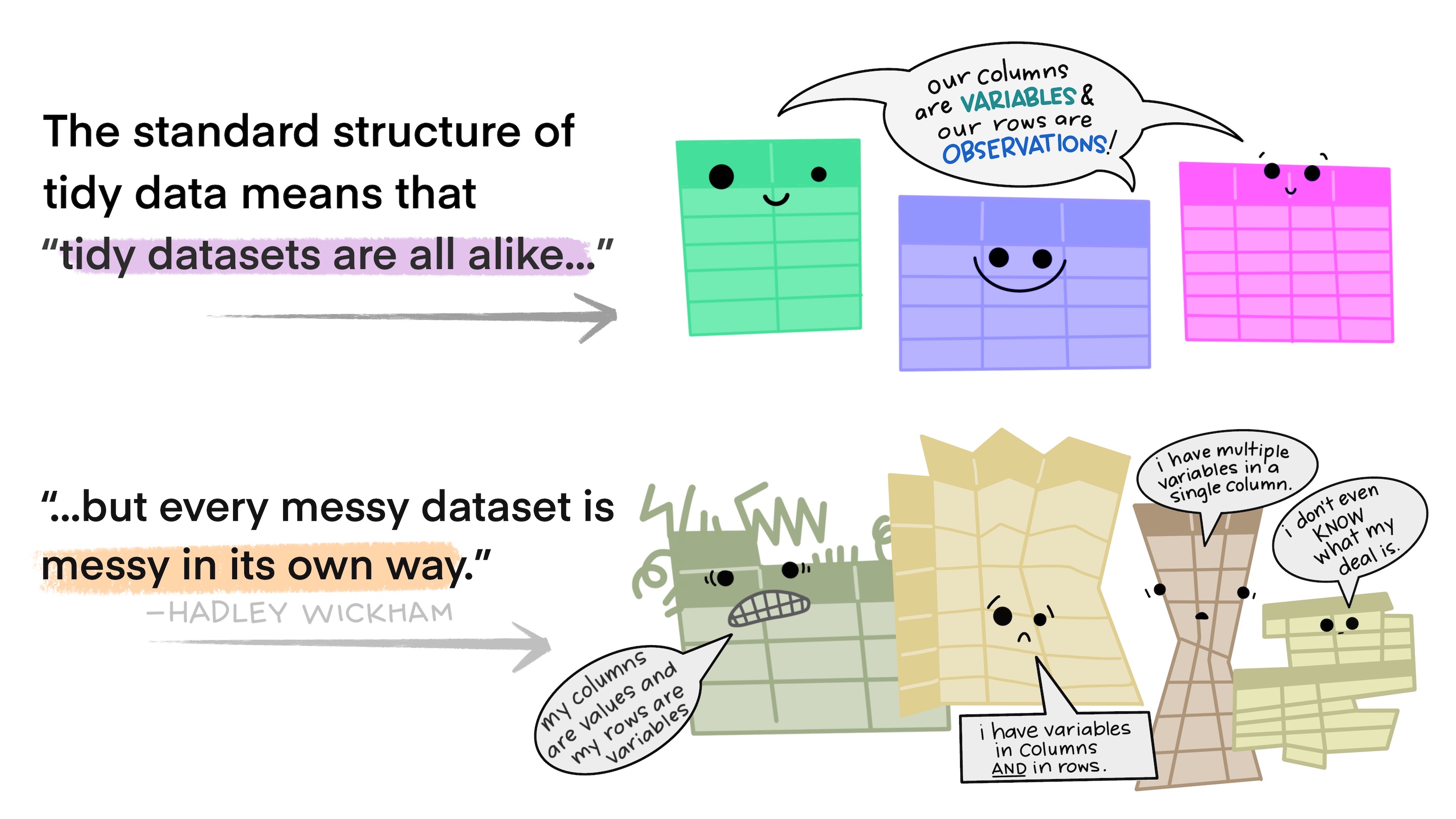
What is Tidy Data?
 1
1
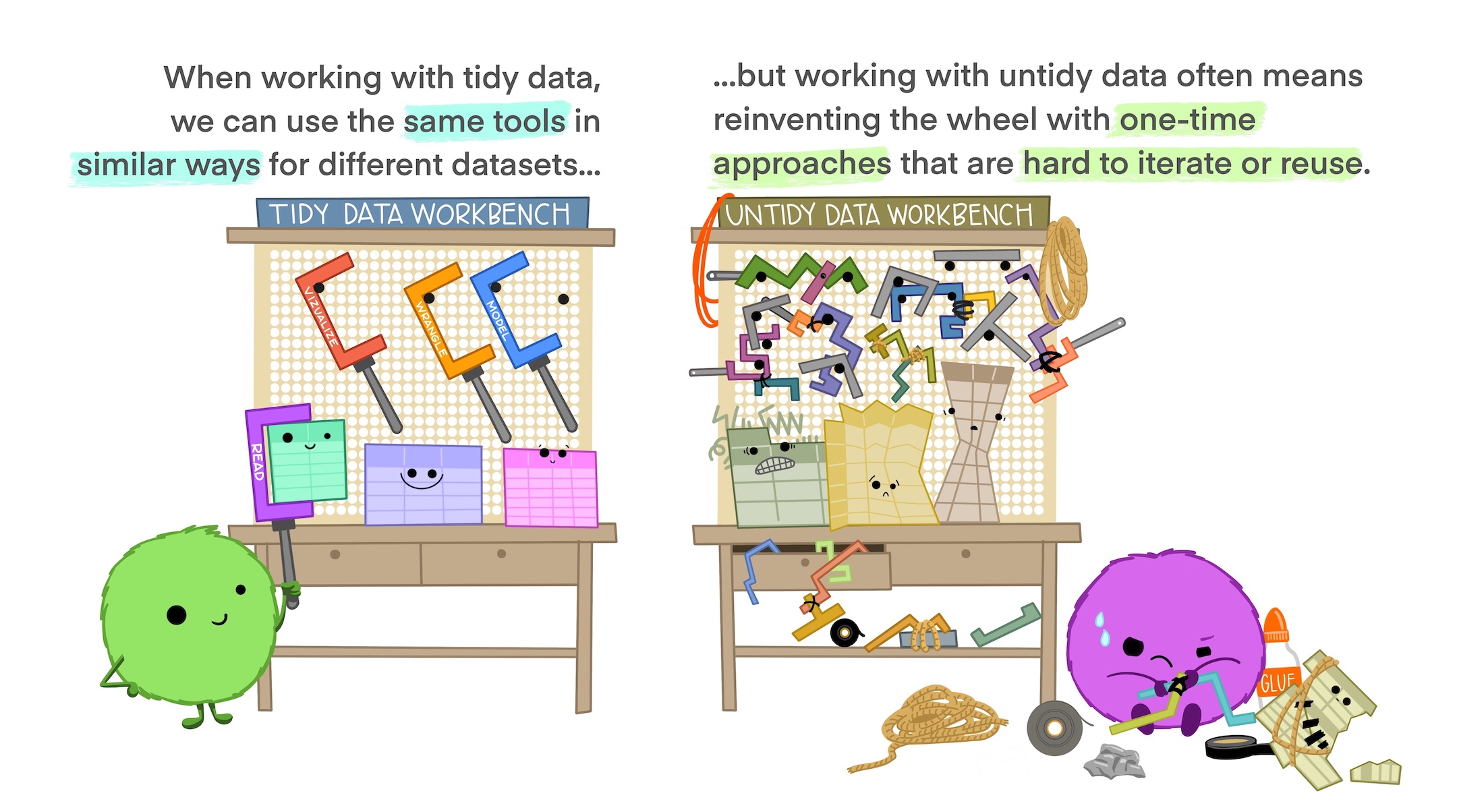
Why do we Want Tidy Data?
- Easier to understand many rows than many columns1
- Required for plotting in
ggplot22 - Required for many types of statistical procedures (e.g. hierarchical or mixed effects models)
- Fewer issues with missing values and “imbalanced” repeated measures data
- Having a consistent method for storing data means it’s easier to learn the tools to work with it since there’s an underlying uniformity.
Most real-world data is not tidy because data are often organized for goals other than analysis (i.e. data entry) and most people aren’t familiar with the principles of tidy data.
Why do we Want Tidy Data?
 1
1
Slightly “Messy” Data
| Program | First Year | Second Year |
|---|---|---|
| Evans School | 10 | 6 |
| Arts & Sciences | 5 | 6 |
| Public Health | 2 | 3 |
| Other | 5 | 1 |
- What is an observation?
- A group of students from a program of a given year
- What are the variables?
- Program, Year
- What are the values?
- Program: Evans School, Arts & Sciences, Public Health, Other
- Year: First, Second – in column headings. Bad!
- Count: spread over two columns!
Tidy Version
| Program | Year | Count |
|---|---|---|
| Evans School | First | 10 |
| Evans School | Second | 6 |
| Arts & Sciences | First | 5 |
| Arts & Sciences | Second | 6 |
| Public Health | First | 2 |
| Public Health | Second | 3 |
| Other | First | 5 |
| Other | Second | 1 |
Each variable is a column.
Each observation is a row.
Each cell has a single value.
Billboard is Just Ugly-Messy
> # A tibble: 10 × 80
> artist track time date.entered wk1 wk2 wk3 wk4 wk5 wk6 wk7
> <chr> <chr> <tim> <date> <int> <int> <int> <int> <int> <int> <int>
> 1 2 Pac Baby… 04:22 2000-02-26 87 82 72 77 87 94 99
> 2 2Ge+her The … 03:15 2000-09-02 91 87 92 NA NA NA NA
> 3 3 Doors D… Kryp… 03:53 2000-04-08 81 70 68 67 66 57 54
> 4 3 Doors D… Loser 04:24 2000-10-21 76 76 72 69 67 65 55
> 5 504 Boyz Wobb… 03:35 2000-04-15 57 34 25 17 17 31 36
> 6 98^0 Give… 03:24 2000-08-19 51 39 34 26 26 19 2
> 7 A*Teens Danc… 03:44 2000-07-08 97 97 96 95 100 NA NA
> 8 Aaliyah I Do… 04:15 2000-01-29 84 62 51 41 38 35 35
> 9 Aaliyah Try … 04:03 2000-03-18 59 53 38 28 21 18 16
> 10 Adams, Yo… Open… 05:30 2000-08-26 76 76 74 69 68 67 61
> # ℹ 69 more variables: wk8 <int>, wk9 <int>, wk10 <int>, wk11 <int>,
> # wk12 <int>, wk13 <int>, wk14 <int>, wk15 <int>, wk16 <int>, wk17 <int>,
> # wk18 <int>, wk19 <int>, wk20 <int>, wk21 <int>, wk22 <int>, wk23 <int>,
> # wk24 <int>, wk25 <int>, wk26 <int>, wk27 <int>, wk28 <int>, wk29 <int>,
> # wk30 <int>, wk31 <int>, wk32 <int>, wk33 <int>, wk34 <int>, wk35 <int>,
> # wk36 <int>, wk37 <int>, wk38 <int>, wk39 <int>, wk40 <int>, wk41 <int>,
> # wk42 <int>, wk43 <int>, wk44 <int>, wk45 <int>, wk46 <int>, wk47 <int>, …Billboard
- What are the observations in the data?
- Song on the Billboard chart each week
- What are the variables in the data?
- Year, artist, track, song length, date entered Hot 100, week since first entered Hot 100 (spread over many columns), rank during week (spread over many columns)
- What are the values in the data?
- e.g. 2000; 3 Doors Down; Kryptonite; 3 minutes 53 seconds; April 8, 2000; Week 3 (stuck in column headings); rank 68 (spread over many columns)
Reminder: Why do we Want Tidy Data?
 1
1
tidyr
The tidyr package provides functions to tidy up data.
Key functions:
-
pivot_longer(): takes a set of columns and pivots them down (“longer”) to make two new columns (which you can name yourself):- A
namecolumn that stores the original column names - A
valuewith the values in those original columns
- A
-
pivot_wider(): invertspivot_longer()by taking two columns and pivoting them up and across (“wider”) into multiple columns
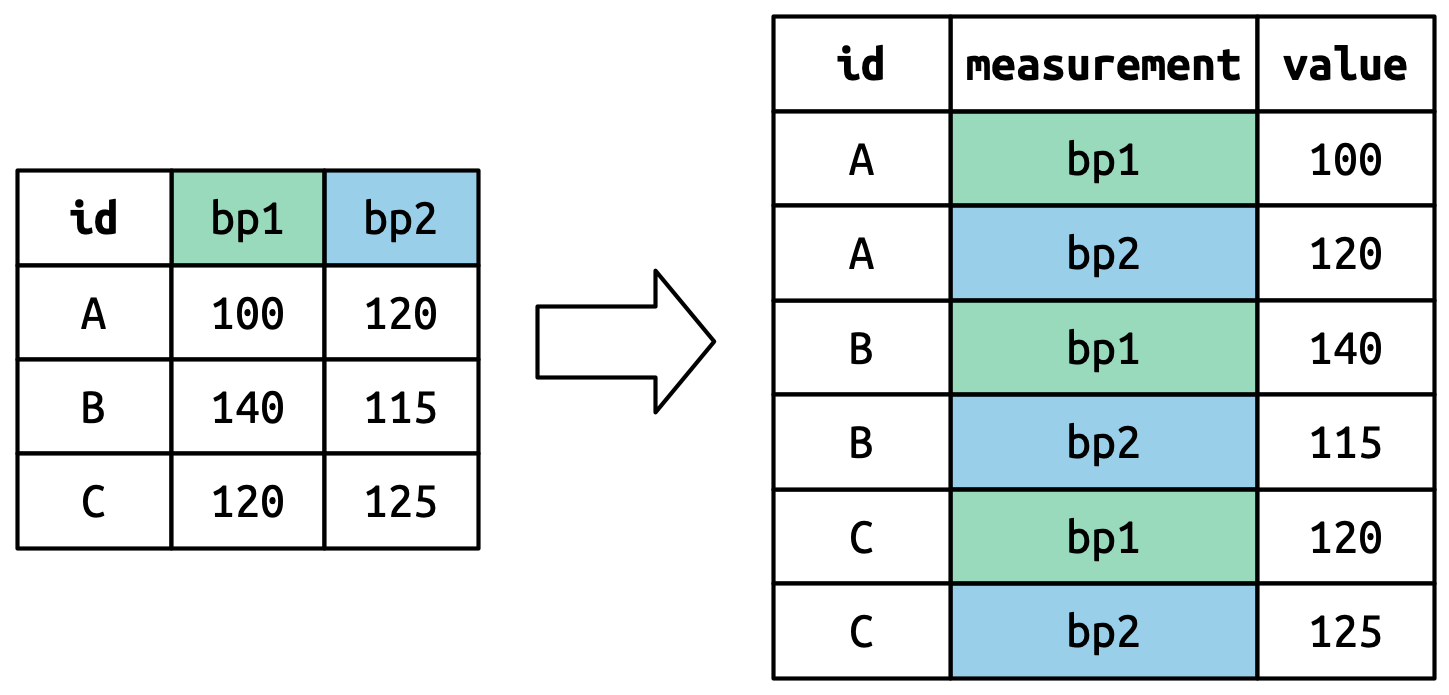
pivot_longer()
This function usually takes three arguments:
-
cols: The columns that need to be pivoted (are not variables) -
names_to: Names the new variable that is stored in multiple columns -
values_to: Names the variable stored in the cell values
pivot_longer()
This function usually takes three arguments:
-
cols: The columns that need to be pivoted (are not variables) names_to: Names the new variable that is stored in multiple columns-
values_to: Names the variable stored in the cell values
pivot_longer()
This function usually takes three arguments:
-
cols: The columns that need to be pivoted (are not variables) -
names_to: Names the new variable that is stored in multiple columns values_to: Names the variable stored in the cell values
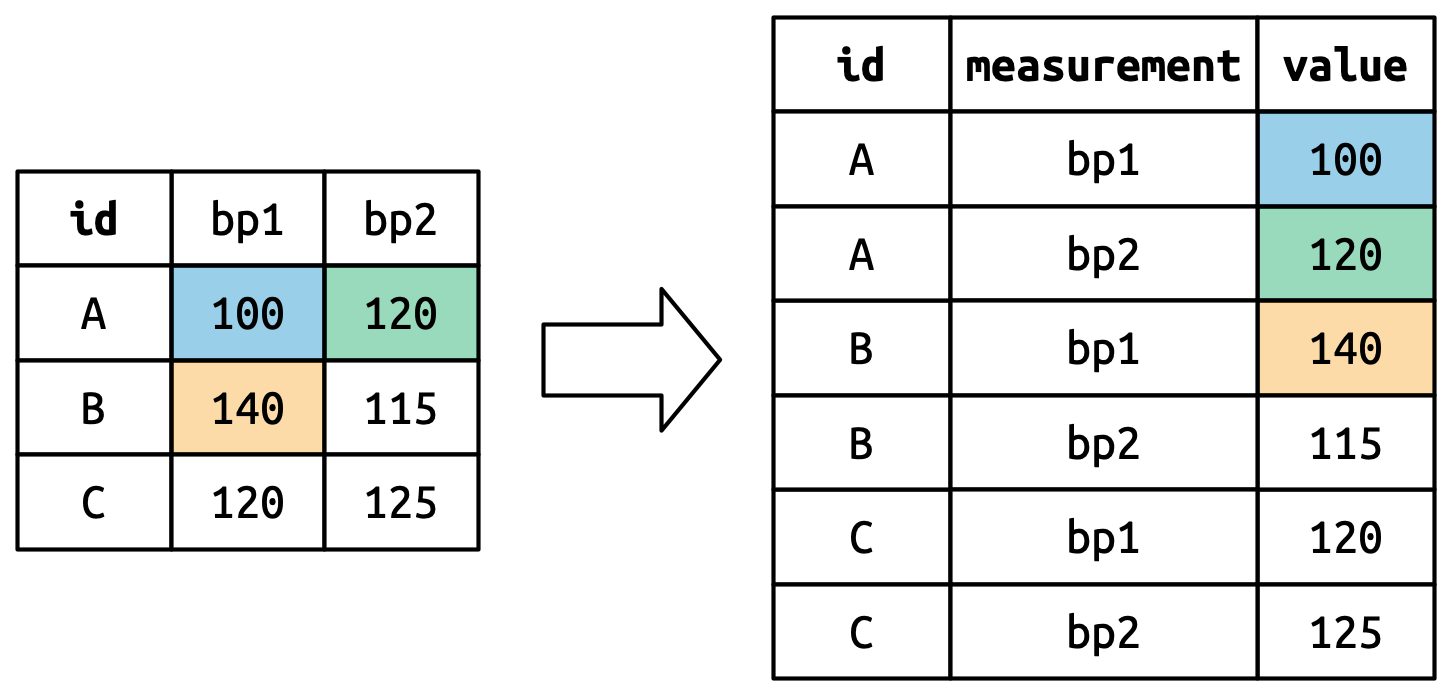
pivot_longer()
This function usually takes three arguments:
-
cols: The columns that need to be pivoted (are not variables) -
names_to: Names the new variable that is stored in multiple columns -
values_to: Names the variable stored in the cell values
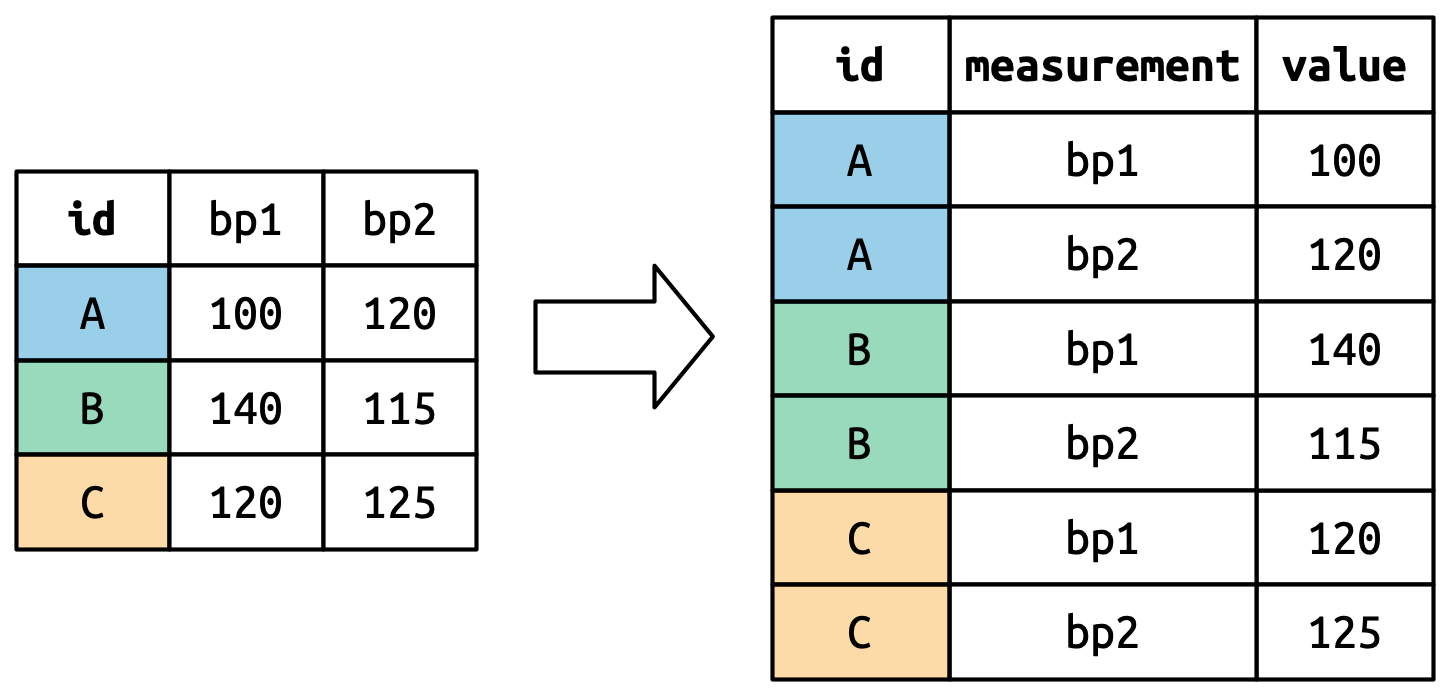
pivot_longer() Example
billboard_2000 <- billboard_renamed |>
pivot_longer(cols = starts_with("wk_"),
names_to ="week",
values_to = "rank")
billboard_2000 |> head(10)- 1
-
billboard_renamedhere has snake_case variable names and correctly specified column types - 2
-
starts_with()is one of the helper functions fromtidyselectthat helps select certain common patterns. We could have also usedcols = wk_1:wk_76. - 3
-
Creates a new variable
weekthat will take values of the current column names we’re pivoting - 4
-
Creates a new variable
valuethat will take the values from the respectivewk_column and row
> # A tibble: 10 × 6
> artist track time date_entered week rank
> <chr> <chr> <time> <date> <chr> <int>
> 1 2 Pac Baby Don't Cry (Keep... 04:22 2000-02-26 wk_1 87
> 2 2 Pac Baby Don't Cry (Keep... 04:22 2000-02-26 wk_2 82
> 3 2 Pac Baby Don't Cry (Keep... 04:22 2000-02-26 wk_3 72
> 4 2 Pac Baby Don't Cry (Keep... 04:22 2000-02-26 wk_4 77
> 5 2 Pac Baby Don't Cry (Keep... 04:22 2000-02-26 wk_5 87
> 6 2 Pac Baby Don't Cry (Keep... 04:22 2000-02-26 wk_6 94
> 7 2 Pac Baby Don't Cry (Keep... 04:22 2000-02-26 wk_7 99
> 8 2 Pac Baby Don't Cry (Keep... 04:22 2000-02-26 wk_8 NA
> 9 2 Pac Baby Don't Cry (Keep... 04:22 2000-02-26 wk_9 NA
> 10 2 Pac Baby Don't Cry (Keep... 04:22 2000-02-26 wk_10 NANow we have a single week column!
Lots of Missing Values?!
> Rows: 24,092
> Columns: 6
> $ artist <chr> "2 Pac", "2 Pac", "2 Pac", "2 Pac", "2 Pac", "2 Pac", "2 …
> $ track <chr> "Baby Don't Cry (Keep...", "Baby Don't Cry (Keep...", "Ba…
> $ time <time> 04:22:00, 04:22:00, 04:22:00, 04:22:00, 04:22:00, 04:22:…
> $ date_entered <date> 2000-02-26, 2000-02-26, 2000-02-26, 2000-02-26, 2000-02-…
> $ week <chr> "wk_1", "wk_2", "wk_3", "wk_4", "wk_5", "wk_6", "wk_7", "…
> $ rank <int> 87, 82, 72, 77, 87, 94, 99, NA, NA, NA, NA, NA, NA, NA, N…It looks like 2 Pac’s song “Baby Don’t Cry” was only on the Billboard Hot 100 for 7 weeks and then dropped off the charts.
Pivoting Better: values_drop_na
Adding the argument values_drop_na = TRUE to pivot_longer() will remove rows with missing ranks. Since these NAs don’t really represent unknown observations (i.e. they were forced to exist by the structure of the dataset) this is an appropriate approach here.
> Min. 1st Qu. Median Mean 3rd Qu. Max.
> 1.00 26.00 51.00 51.05 76.00 100.00And way fewer rows!
parse_number()
The week column is of the type character, but it should be numeric.
> [1] "wk_1" "wk_2" "wk_3" "wk_4" "wk_5" "wk_6"parse_number() grabs just the numeric information from a character string:
- 1
-
You can use
mutate()to overwrite existing columns.
> Min. 1st Qu. Median Mean 3rd Qu. Max.
> 1.00 5.00 10.00 11.47 16.00 65.00More sophisticated tools for character strings will be covered later in this course!
Use pivot_longer arguments
Alternatively (and more efficiently), there are a number of optional arguments for pivot_longer that are meant to help deal with naming issues.
billboard_2000 <- billboard_renamed |>
pivot_longer(starts_with("wk_"),
names_to = "week",
values_to = "rank",
values_drop_na = TRUE,
names_prefix = "wk_",
names_transform = list(week = as.integer))
head(billboard_2000, 5)- 1
-
names_prefixis used to remove “wk_” from the values ofweek - 2
-
names_transformconvertsweekinto an integer number. We’ll coverlists in more detail next week but this is the structure required for this argument and it flexibly allows for multiple naming transformations to be applied at once.
> # A tibble: 5 × 6
> artist track time date_entered week rank
> <chr> <chr> <time> <date> <int> <int>
> 1 2 Pac Baby Don't Cry (Keep... 04:22 2000-02-26 1 87
> 2 2 Pac Baby Don't Cry (Keep... 04:22 2000-02-26 2 82
> 3 2 Pac Baby Don't Cry (Keep... 04:22 2000-02-26 3 72
> 4 2 Pac Baby Don't Cry (Keep... 04:22 2000-02-26 4 77
> 5 2 Pac Baby Don't Cry (Keep... 04:22 2000-02-26 5 87Multiple Variables in Column Names
A more challenging situation occurs when you have multiple pieces of information crammed into the column names, and you would like to store these in separate new variables.
This dataset contains tuberculosis diagnoses collected by the World Health Organization.
> # A tibble: 7,240 × 58
> country year sp_m_014 sp_m_1524 sp_m_2534 sp_m_3544 sp_m_4554 sp_m_5564
> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
> 1 Afghanistan 1980 NA NA NA NA NA NA
> 2 Afghanistan 1981 NA NA NA NA NA NA
> 3 Afghanistan 1982 NA NA NA NA NA NA
> 4 Afghanistan 1983 NA NA NA NA NA NA
> 5 Afghanistan 1984 NA NA NA NA NA NA
> 6 Afghanistan 1985 NA NA NA NA NA NA
> 7 Afghanistan 1986 NA NA NA NA NA NA
> 8 Afghanistan 1987 NA NA NA NA NA NA
> 9 Afghanistan 1988 NA NA NA NA NA NA
> 10 Afghanistan 1989 NA NA NA NA NA NA
> # ℹ 7,230 more rows
> # ℹ 50 more variables: sp_m_65 <dbl>, sp_f_014 <dbl>, sp_f_1524 <dbl>,
> # sp_f_2534 <dbl>, sp_f_3544 <dbl>, sp_f_4554 <dbl>, sp_f_5564 <dbl>,
> # sp_f_65 <dbl>, sn_m_014 <dbl>, sn_m_1524 <dbl>, sn_m_2534 <dbl>,
> # sn_m_3544 <dbl>, sn_m_4554 <dbl>, sn_m_5564 <dbl>, sn_m_65 <dbl>,
> # sn_f_014 <dbl>, sn_f_1524 <dbl>, sn_f_2534 <dbl>, sn_f_3544 <dbl>,
> # sn_f_4554 <dbl>, sn_f_5564 <dbl>, sn_f_65 <dbl>, ep_m_014 <dbl>, …The first two columns are self explanatory but what’s going on with the rest?
Multiple Variables in Column Names
Data documentation and some minor investigation would lead you to figure out that the three elements in each of these column names are actually data!
- 1
- Remove the first two columns to see the more mysteriously-named variables.
> [1] "sp_m_014" "sp_m_1524" "sp_m_2534" "sp_m_3544" "sp_m_4554"
> [6] "sp_m_5564" "sp_m_65" "sp_f_014" "sp_f_1524" "sp_f_2534"
> [11] "sp_f_3544" "sp_f_4554" "sp_f_5564" "sp_f_65" "sn_m_014"
> [16] "sn_m_1524" "sn_m_2534" "sn_m_3544" "sn_m_4554" "sn_m_5564"
> [21] "sn_m_65" "sn_f_014" "sn_f_1524" "sn_f_2534" "sn_f_3544"
> [26] "sn_f_4554" "sn_f_5564" "sn_f_65" "ep_m_014" "ep_m_1524"
> [31] "ep_m_2534" "ep_m_3544" "ep_m_4554" "ep_m_5564" "ep_m_65"
> [36] "ep_f_014" "ep_f_1524" "ep_f_2534" "ep_f_3544" "ep_f_4554"
> [41] "ep_f_5564" "ep_f_65" "rel_m_014" "rel_m_1524" "rel_m_2534"
> [46] "rel_m_3544" "rel_m_4554" "rel_m_5564" "rel_m_65" "rel_f_014"
> [51] "rel_f_1524" "rel_f_2534" "rel_f_3544" "rel_f_4554" "rel_f_5564"
> [56] "rel_f_65"Multiple Variables in Column Names
who2 |>
pivot_longer(
cols = !(country:year),
names_to = c("diagnosis", "gender", "age"),
names_sep = "_",
values_to = "count"
)- 1
-
You can also exclude variables by negating a vector of them.
- 2
-
names_toallows you to specify how to split up the current column names into new column names. - 3
-
You can use
names_patterninstead ofnames_septo extract variables from more complicated naming scenarios once you’ve learned regular expressions. You’ll get a basic introduction to them in a few weeks.
> # A tibble: 405,440 × 6
> country year diagnosis gender age count
> <chr> <dbl> <chr> <chr> <chr> <dbl>
> 1 Afghanistan 1980 sp m 014 NA
> 2 Afghanistan 1980 sp m 1524 NA
> 3 Afghanistan 1980 sp m 2534 NA
> 4 Afghanistan 1980 sp m 3544 NA
> 5 Afghanistan 1980 sp m 4554 NA
> 6 Afghanistan 1980 sp m 5564 NA
> 7 Afghanistan 1980 sp m 65 NA
> 8 Afghanistan 1980 sp f 014 NA
> 9 Afghanistan 1980 sp f 1524 NA
> 10 Afghanistan 1980 sp f 2534 NA
> # ℹ 405,430 more rowsVariable & Values in Column Names
This dataset contains data about five families, with the names and dates of birth of up to two children.
> # A tibble: 5 × 5
> family dob_child1 dob_child2 name_child1 name_child2
> <int> <date> <date> <chr> <chr>
> 1 1 1998-11-26 2000-01-29 Susan Jose
> 2 2 1996-06-22 NA Mark <NA>
> 3 3 2002-07-11 2004-04-05 Sam Seth
> 4 4 2004-10-10 2009-08-27 Craig Khai
> 5 5 2000-12-05 2005-02-28 Parker GracieThe new challenge in this dataset is that the column names contain the names of two variables (dob, name) and the values of another (child, with values 1 or 2).
Variable & Values in Column Names
- 1
-
.valueisn’t the name of a variable but a unique value that tellspivot_longerto use the first component of the pivoted column name as a variable name in the output. - 2
-
Using
values_drop_na = TRUEagain since not every family has 2 children.
> # A tibble: 9 × 4
> family child dob name
> <int> <chr> <date> <chr>
> 1 1 child1 1998-11-26 Susan
> 2 1 child2 2000-01-29 Jose
> 3 2 child1 1996-06-22 Mark
> 4 3 child1 2002-07-11 Sam
> 5 3 child2 2004-04-05 Seth
> 6 4 child1 2004-10-10 Craig
> 7 4 child2 2009-08-27 Khai
> 8 5 child1 2000-12-05 Parker
> 9 5 child2 2005-02-28 Gracie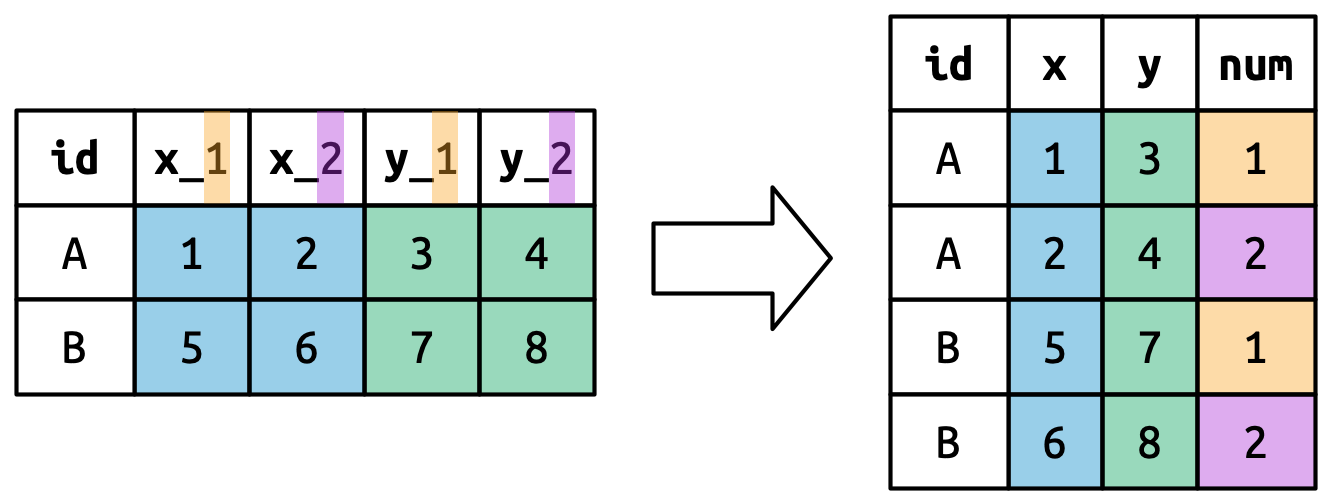
pivot_wider
pivot_wider() is the opposite of pivot_longer(), which you use if you have data for the same observation taking up multiple rows.
Here’s an example of data that we probably want to pivot wider (unless we want to plot each statistic in its own facet):
> # A tibble: 6 × 3
> Group Statistic Value
> <chr> <chr> <dbl>
> 1 A Mean 1.28
> 2 A Median 1
> 3 A SD 0.72
> 4 B Mean 2.81
> 5 B Median 2
> 6 B SD 1.33A common cue to use pivot_wider() is having measurements of different quantities in the same column.
pivot_wider Example
wide_stats <- long_stats |>
pivot_wider(id_cols = Group,
names_from = Statistic,
values_from = Value)
wide_stats- 1
-
id_colsis the column that uniquely identifies each row in the new dataset. Default is everything not innames_fromandvalues_from. - 2
-
names_fromprovides the names that will be used for the new columns - 3
-
values_fromprovides the values that will be used to populate the cells of the new columns.
> # A tibble: 2 × 4
> Group Mean Median SD
> <chr> <dbl> <dbl> <dbl>
> 1 A 1.28 1 0.72
> 2 B 2.81 2 1.33pivot_wider() also has a number of optional names_* and values_* arguments for more complicated transformations.
Nested Data
If there are multiple rows in the input that correspond to one cell in the output you’ll get a list-column.
This means that you:
1) need to fix something in your code/data because it shouldn’t be nested in this way or
2) need to use unnest_wider() or unnest_longer() in order to access this column of data.
More on this here.
Lab
Importing & Tidying Data
- Go to the Lecture 5 Homepage and click on the link
Religion & Incomeunder the Data section. - Click File > Save to download this data to the same folder where your source document1 will be saved for this lab.
- Read in your data using the appropriate function from
readr. - Pivot your data to make it tidy2.
Break!
Data types in R
Going back to our list of data types in R:
- Logicals
- Factors
- Date/Date-time
- Numbers
- Missing Values
- Strings
Data types in R
Going back to our list of data types in R:
Logicals- Factors
- Date/Date-time
- Numbers
- Missing Values
- Strings
Data types in R
Going back to our list of data types in R:
Logicals- Factors
- Date/Date-time
- Numbers
- Missing Values
- Strings
Working with Factors
Why Use Factors?
Factors are a special class of data specifically for categorical variables1 which have a fixed, known, and mutually exclusive set of possible values2.
Imagine we have a variable that records the month that an event occurred.
The two main issues with coding this simply as a character string are that:
- It doesn’t help catch spelling errors and that
Factors
Factors have an additional specification called levels. These are the categories of the categorical variable. We can create a vector of the levels first:
And then we can create a factor like so:
Creating Factors
factor is Base R’s function for creating factors while fct is forcats function for making factors. A couple of things to note about their differences:
factor
- Any values not specified as a level will be silently converted to
NA - Without specified levels, they’ll be created from the data in alphabetical order1
fct
- Will send a error message if a value exists outside the specified levels
- Without specified levels, they’ll be created from the data in order of first appearance
You can create a factor by specifying col_factor() when reading in data with readr:
If you need to access the levels directly you can use the Base R function levels().
Changing the Order of Levels
One of the more common data manipulations you’ll want to do with factors is to change the ordering of the levels. This could be to put them in a more intuitive order but also to make a visualization clearer and more impactful.
Let’s use a subset of the General Social Survey1 data to see what this might look like.
> # A tibble: 21,483 × 9
> year marital age race rincome partyid relig denom tvhours
> <int> <fct> <int> <fct> <fct> <fct> <fct> <fct> <int>
> 1 2000 Never married 26 White $8000 to 9999 Ind,near … Prot… Sout… 12
> 2 2000 Divorced 48 White $8000 to 9999 Not str r… Prot… Bapt… NA
> 3 2000 Widowed 67 White Not applicable Independe… Prot… No d… 2
> 4 2000 Never married 39 White Not applicable Ind,near … Orth… Not … 4
> 5 2000 Divorced 25 White Not applicable Not str d… None Not … 1
> 6 2000 Married 25 White $20000 - 24999 Strong de… Prot… Sout… NA
> 7 2000 Never married 36 White $25000 or more Not str r… Chri… Not … 3
> 8 2000 Divorced 44 White $7000 to 7999 Ind,near … Prot… Luth… NA
> 9 2000 Married 44 White $25000 or more Not str d… Prot… Other 0
> 10 2000 Married 47 White $25000 or more Strong re… Prot… Sout… 3
> # ℹ 21,473 more rowsChanging the Order of Levels
There are four related functions to change the level ordering in forcats.
fct_reorder()
- 1
-
factoris the factor to reorder (or a character string to be turned into a factor) - 2
-
ordering_vectorspecifies how to reorderfactor - 3
-
optional_functionis applied if there are multiple values ofordering_vectorfor each value offactor(the default is to take the median)
fct_relevel()
fct_reorder2()
fct_infreq()
- 7
-
fct_infreqreordersfactorin decreasing frequency. See other variations here. Use withfct_rev()for increasing frequency.
Changing the Order of Levels
There are four related functions to change the level ordering in forcats.
Without fct_reorder()
Code

With fct_reorder()

Without fct_relevel()
Code

With fct_relevel()

Without fct_reorder2()
Code

With fct_reorder()

Without fct_infreq()

With fct_infreq()

Changing the Value of Levels
You may also want to change the actual values of your factor levels. The main way to do this is fct_recode().
- 1
-
You can use
count()to get the full list of levels for a variable and their respective counts.
> # A tibble: 10 × 2
> partyid n
> <fct> <int>
> 1 No answer 154
> 2 Don't know 1
> 3 Other party 393
> 4 Strong republican 2314
> 5 Not str republican 3032
> 6 Ind,near rep 1791
> 7 Independent 4119
> 8 Ind,near dem 2499
> 9 Not str democrat 3690
> 10 Strong democrat 3490fct_recode()
gss_cat |>
mutate(
partyid = fct_recode(partyid,
"Republican, strong" = "Strong republican",
"Republican, weak" = "Not str republican",
"Independent, near rep" = "Ind,near rep",
"Independent, near dem" = "Ind,near dem",
"Democrat, weak" = "Not str democrat",
"Democrat, strong" = "Strong democrat"
)
) |>
count(partyid)> # A tibble: 10 × 2
> partyid n
> <fct> <int>
> 1 No answer 154
> 2 Don't know 1
> 3 Other party 393
> 4 Republican, strong 2314
> 5 Republican, weak 3032
> 6 Independent, near rep 1791
> 7 Independent 4119
> 8 Independent, near dem 2499
> 9 Democrat, weak 3690
> 10 Democrat, strong 3490Some features of fct_recode():
- Will leave the levels that aren’t explicitly mentioned, as is.
- Will warn you if you accidentally refer to a level that doesn’t exist.
- You can combine groups by assigning multiple old levels to the same new level.
fct_collapse()
A useful variant of fct_recode() is fct_collapse() which will allow you to collapse a lot of levels at once.
gss_cat |>
mutate(
partyid = fct_collapse(partyid,
"other" = c("No answer", "Don't know", "Other party"),
"rep" = c("Strong republican", "Not str republican"),
"ind" = c("Ind,near rep", "Independent", "Ind,near dem"),
"dem" = c("Not str democrat", "Strong democrat")
)
) |>
count(partyid)> # A tibble: 4 × 2
> partyid n
> <fct> <int>
> 1 other 548
> 2 rep 5346
> 3 ind 8409
> 4 dem 7180fct_lump_*
Sometimes you’ll have several levels of a variable that have a small enough N to warrant grouping them together into an other category. The family of fct_lump_* functions are designed to help with this.
- 1
-
Other functions include:
fct_lump_min(),fct_lump_prop(),fct_lump_lowfreq(). Read more about them here.
> # A tibble: 10 × 2
> relig n
> <fct> <int>
> 1 Protestant 10846
> 2 Catholic 5124
> 3 None 3523
> 4 Christian 689
> 5 Other 458
> 6 Jewish 388
> 7 Buddhism 147
> 8 Inter-nondenominational 109
> 9 Moslem/islam 104
> 10 Orthodox-christian 95Ordered Factors
So far we’ve mostly been discussing how to code nominal variables, or categorical variables that have no inherent ordering.
If you want to specify that your factor has a strict order you can classify it as a ordered factor.
- 1
- Ordered factors imply a strict ordering and equal distance between levels: the first level is “less than” the second level by the same amount that the second level is “less than” the third level, and so on.
> [1] a b c
> Levels: a < b < cIn practice there are only two ways in which ordered factors are different than factors:
-
scale_color_viridis()/scale_fill_viridis()will be used automatically when mapping an ordered factor inggplot2because it implies an ordered ranking - If you use an ordered function in a linear model, it will use “polygonal contrasts”. You can learn more about what this means here.
Lab
Importing & Tidying Data
- Go to the Lecture 5 Homepage and click on the link
Religion & Incomeunder the Data section. - Click File > Save to download this data to the same folder where your source document1 will be saved for this lab.
- Read in your data using the appropriate function from
readr. - Pivot your data to make it tidy2.
- Turn two of the variables into factors3.
Wrangling Date/
Date-Time Data
Date and Date-Time
While they may look like character strings, Dates, Date-Times and Times1 are each separate classes of data.
Data Type
- Date
- Date
- Date-Time
- Date-Time
- Time
Package
baselubridatebaselubridatehms
Reference in R
POSIXctdatePOSIXltdttmtime
Dates and times are challenging data types because there are physical properties but also additional geopolitical definitions that don’t always neatly align with physical reality.
Creating Dates/Date-Times
If your data is in ISO8601 date or date-time format1 readr will automatically recognize it and read it in as a date/date-time.
If you’re reading in a different date/date-time format you can use col_types plus col_date() or col_datetime() along with a date-time format.
| Type | Code | Meaning | Example |
|---|---|---|---|
| Year | %Y |
4 digit year | 2021 |
%y |
2 digit year | 21 | |
| Month | %m |
Number | 2 |
%b |
Abbreviated name | Feb | |
%B3
|
Full name | February | |
| Day | %d |
Two digits | 02 |
%e |
One or two digits | 2 | |
| Time | %H |
24-hour hour | 13 |
%I |
12-hour hour | 1 | |
%p |
AM/PM | pm | |
%M |
Minutes | 35 | |
%S |
Seconds | 45 | |
%OS |
Seconds with decimal component | 45.35 | |
%Z |
Time zone name | America/Chicago | |
%z |
Offset from UTC | +0800 | |
| Other | %. |
Skip one non-digit | : |
%* |
Skip any number of non-digits |
You can also use lubridate’s helper functions to specify a date format automatically.
> [1] "2017-01-31"> [1] "2017-01-31"> [1] "2017-01-31"If you need to specify a date-time you can use these helper functions:
> [1] "2017-01-31 20:11:59 UTC"> [1] "2017-01-31 08:01:00 UTC"If you have time elements in separate variables, like in the flights dataset…
> # A tibble: 336,776 × 5
> year month day hour minute
> <int> <int> <int> <dbl> <dbl>
> 1 2013 1 1 5 15
> 2 2013 1 1 5 29
> 3 2013 1 1 5 40
> 4 2013 1 1 5 45
> 5 2013 1 1 6 0
> 6 2013 1 1 5 58
> 7 2013 1 1 6 0
> 8 2013 1 1 6 0
> 9 2013 1 1 6 0
> 10 2013 1 1 6 0
> # ℹ 336,766 more rows…you can use make_date or make_datetime to create your date/time object.
> # A tibble: 336,776 × 6
> year month day hour minute departure
> <int> <int> <int> <dbl> <dbl> <dttm>
> 1 2013 1 1 5 15 2013-01-01 05:15:00
> 2 2013 1 1 5 29 2013-01-01 05:29:00
> 3 2013 1 1 5 40 2013-01-01 05:40:00
> 4 2013 1 1 5 45 2013-01-01 05:45:00
> 5 2013 1 1 6 0 2013-01-01 06:00:00
> 6 2013 1 1 5 58 2013-01-01 05:58:00
> 7 2013 1 1 6 0 2013-01-01 06:00:00
> 8 2013 1 1 6 0 2013-01-01 06:00:00
> 9 2013 1 1 6 0 2013-01-01 06:00:00
> 10 2013 1 1 6 0 2013-01-01 06:00:00
> # ℹ 336,766 more rows
as_datetime() and as_date() are used to coerce existing date/time objects into their counterpart.
While ISO8601 format is read in as a string of human-readable date/times, another common date/time format, Unix time, is represented by the number of seconds that have elapsed since 1 January 1970 at 0:00:00 UTC.
Extracting Time Components
We’ve discussed how to make a date/time object from individual components using make_date() and make_datetime() but what if you need to extract an element from a date/time?
There are a number of accessor functions that allow you to do just that.
datetime <- ymd_hms("2020-01-30 12:30:45")
year(datetime)
month(datetime)
mday(datetime)
yday(datetime)
wday(datetime)
hour(datetime)
minute(datetime)
second(datetime)- 1
-
You can set
label = TRUEto return the abbreviated name andabbr = FALSEto return the full name (i.e.month(datetime, label = TRUE)returns Jan andmonth(datetime, label = TRUE, abbr = FALSE)returns January) - 2
- Day of the month.
- 3
- Day of the year.
- 4
-
Day of the week. You can set
label = TRUEto return the abbreviated name andabbr = FALSEto return the full name (i.e.wday(datetime, label = TRUE)returns Thu andwday(datetime, label = TRUE, abbr = FALSE)returns Thursday)
> [1] 2020
> [1] 1
> [1] 30
> [1] 30
> [1] 5
> [1] 12
> [1] 30
> [1] 45Changing Date/Times
While less common, you may need to recode a date/time variable which you can also do with these accessor functions.
An alternative1 way to do this is by using update():
A nice feature of this function is that if values are too big for the unit in question, they will automatically roll over:
Rounding Dates
Alternatively, you can round your date/time objects to a nearby unit with these three functions: floor_date(), round_date(), and ceiling_date().
datetime <- ymd_hms("2020-01-30 08:05:35")
floor_date(datetime, unit = "week")
round_date(datetime, unit = "week", week_start = 1)
ceiling_date(datetime, unit = "hour")- 1
-
These functions take 3 arguments: a date/time vector, a unit of time to round by (valid base units include
second,minute,hour,day,week,month,bimonth,quarter,season,halfyearandyear), and the day of the week that the week starts (default is 7, or Sunday).
> [1] "2020-01-26 UTC"
> [1] "2020-01-27 UTC"
> [1] "2020-01-30 09:00:00 UTC"Spans of time
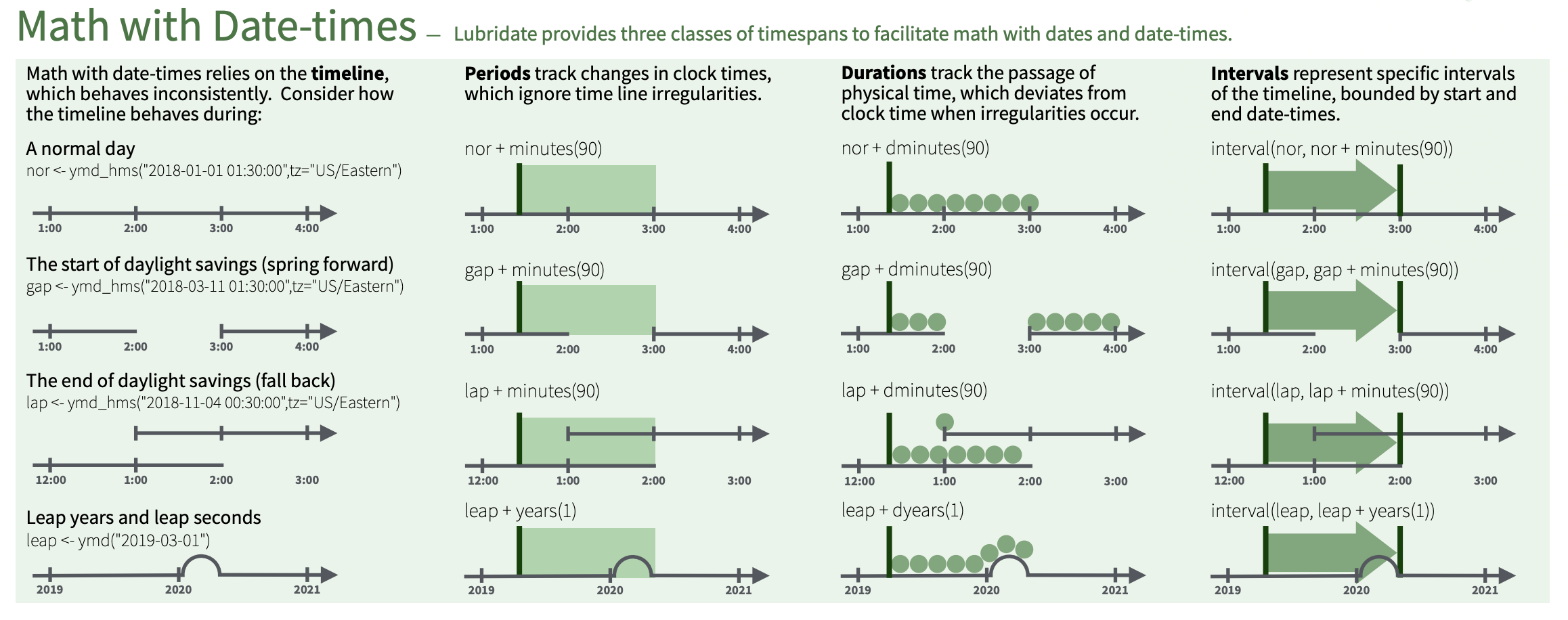
There are three different timespan classes in lubridate, which reflect the complexity of date/time data.
Durations
Durations represent precise physical time. When you subtract two dates, you’ll get a difftime object.
- 1
-
difftimeobjects record time spans in seconds, minutes, hours, days, or weeks. This is fairly ambiguous solubridateprovides a more consistent alternative: theduration, which always uses seconds. - 2
- Larger units are created by converting minutes, hours, days, weeks, and years to seconds.
> Time difference of 885 days
> [1] "76464000s (~2.42 years)"There are a variety of constructors to create durations:
- 1
- Aggregating to larger time units is more problematic. A year uses the “average” number of days in a year, i.e. 365.25. There’s no way to convert a month to a duration, because there’s just too much variation.
> [1] "15s"
> [1] "600s (~10 minutes)"
> [1] "43200s (~12 hours)" "86400s (~1 days)"
> [1] "0s" "86400s (~1 days)" "172800s (~2 days)"
> [4] "259200s (~3 days)" "345600s (~4 days)" "432000s (~5 days)"
> [1] "1814400s (~3 weeks)"
> [1] "31557600s (~1 years)"Math with Durations
You can add and multiply durations:
> [1] "63115200s (~2 years)"> [1] "38869200s (~1.23 years)"Sometimes you’ll get an unexpected results though:
- 1
- Daylight Savings Time is a human construction so March 8th only has 23 hours because it’s when DST starts. If we add a full days worth of seconds we end up with a different time and a different time zone.
> [1] "2026-03-08 01:00:00 EST"
> [1] "2026-03-09 02:00:00 EDT"For this reason, lubridate also has periods.
Periods
Periods represent “human” times like days and months and therefore do not have a fixed length in seconds.
Periods also have their own constructor functions:
Math with Periods
We can add and multiply periods:
> [1] "60m 10d 0H 0M 0S"> [1] "50d 25H 2M 0S"And also add them to dates.
# A leap year
ymd("2024-01-01") + dyears(1)
ymd("2024-01-01") + years(1)
# Daylight saving time
one_am + ddays(1)
one_am + days(1)- 1
- Periods are more likely than durations to do what you expect.
> [1] "2024-12-31 06:00:00 UTC"
> [1] "2025-01-01"
> [1] "2026-03-09 02:00:00 EDT"
> [1] "2026-03-09 01:00:00 EDT"Intervals
Intervals represent the length of a time span in human units. You can think of it as a duration with a starting point.
Imagine we wanted to know how many days are in a year?
To be more accurate we need to give the specific range of time in questions.
y2023 <- ymd("2023-01-01") %--% ymd("2024-01-01")
y2024 <- ymd("2024-01-01") %--% ymd("2025-01-01")
y2023
y2024
y2023 / days(1)
y2024 / days(1)- 3
-
You can create an interval by writing
start %--% end. - 4
- Now when we do this math we get the exact number of “human” days within the span of dates we specified.
> [1] 2023-01-01 UTC--2024-01-01 UTC
> [1] 2024-01-01 UTC--2025-01-01 UTC
> [1] 365
> [1] 366Time zones
Time zones are a very complicated topic because different places have different rules which can, or already have, change(d) over time! To really clarify things R uses the international standard IANA time zones which use a consistent naming scheme: {area}/{location}.
- 1
-
Use
Sys.timezone()to find out which timezoneRthinks you’re in.
> [1] "America/Los_Angeles"- 2
-
See the complete list of all time zone names with
OlsonNames()
> [1] "Africa/Abidjan" "Africa/Accra"
> [3] "Africa/Addis_Ababa" "Africa/Algiers"
> [5] "Africa/Asmara" "Africa/Asmera"
> [7] "Africa/Bamako" "Africa/Bangui"
> [9] "Africa/Banjul" "Africa/Bissau"
> [11] "Africa/Blantyre" "Africa/Brazzaville"
> [13] "Africa/Bujumbura" "Africa/Cairo"
> [15] "Africa/Casablanca" "Africa/Ceuta"
> [17] "Africa/Conakry" "Africa/Dakar"
> [19] "Africa/Dar_es_Salaam" "Africa/Djibouti"
> [21] "Africa/Douala" "Africa/El_Aaiun"
> [23] "Africa/Freetown" "Africa/Gaborone"
> [25] "Africa/Harare" "Africa/Johannesburg"
> [27] "Africa/Juba" "Africa/Kampala"
> [29] "Africa/Khartoum" "Africa/Kigali"
> [31] "Africa/Kinshasa" "Africa/Lagos"
> [33] "Africa/Libreville" "Africa/Lome"
> [35] "Africa/Luanda" "Africa/Lubumbashi"
> [37] "Africa/Lusaka" "Africa/Malabo"
> [39] "Africa/Maputo" "Africa/Maseru"
> [41] "Africa/Mbabane" "Africa/Mogadishu"
> [43] "Africa/Monrovia" "Africa/Nairobi"
> [45] "Africa/Ndjamena" "Africa/Niamey"
> [47] "Africa/Nouakchott" "Africa/Ouagadougou"
> [49] "Africa/Porto-Novo" "Africa/Sao_Tome"
> [51] "Africa/Timbuktu" "Africa/Tripoli"
> [53] "Africa/Tunis" "Africa/Windhoek"
> [55] "America/Adak" "America/Anchorage"
> [57] "America/Anguilla" "America/Antigua"
> [59] "America/Araguaina" "America/Argentina/Buenos_Aires"
> [61] "America/Argentina/Catamarca" "America/Argentina/ComodRivadavia"
> [63] "America/Argentina/Cordoba" "America/Argentina/Jujuy"
> [65] "America/Argentina/La_Rioja" "America/Argentina/Mendoza"
> [67] "America/Argentina/Rio_Gallegos" "America/Argentina/Salta"
> [69] "America/Argentina/San_Juan" "America/Argentina/San_Luis"
> [71] "America/Argentina/Tucuman" "America/Argentina/Ushuaia"
> [73] "America/Aruba" "America/Asuncion"
> [75] "America/Atikokan" "America/Atka"
> [77] "America/Bahia" "America/Bahia_Banderas"
> [79] "America/Barbados" "America/Belem"
> [81] "America/Belize" "America/Blanc-Sablon"
> [83] "America/Boa_Vista" "America/Bogota"
> [85] "America/Boise" "America/Buenos_Aires"
> [87] "America/Cambridge_Bay" "America/Campo_Grande"
> [89] "America/Cancun" "America/Caracas"
> [91] "America/Catamarca" "America/Cayenne"
> [93] "America/Cayman" "America/Chicago"
> [95] "America/Chihuahua" "America/Ciudad_Juarez"
> [97] "America/Coral_Harbour" "America/Cordoba"
> [99] "America/Costa_Rica" "America/Coyhaique"
> [101] "America/Creston" "America/Cuiaba"
> [103] "America/Curacao" "America/Danmarkshavn"
> [105] "America/Dawson" "America/Dawson_Creek"
> [107] "America/Denver" "America/Detroit"
> [109] "America/Dominica" "America/Edmonton"
> [111] "America/Eirunepe" "America/El_Salvador"
> [113] "America/Ensenada" "America/Fort_Nelson"
> [115] "America/Fort_Wayne" "America/Fortaleza"
> [117] "America/Glace_Bay" "America/Godthab"
> [119] "America/Goose_Bay" "America/Grand_Turk"
> [121] "America/Grenada" "America/Guadeloupe"
> [123] "America/Guatemala" "America/Guayaquil"
> [125] "America/Guyana" "America/Halifax"
> [127] "America/Havana" "America/Hermosillo"
> [129] "America/Indiana/Indianapolis" "America/Indiana/Knox"
> [131] "America/Indiana/Marengo" "America/Indiana/Petersburg"
> [133] "America/Indiana/Tell_City" "America/Indiana/Vevay"
> [135] "America/Indiana/Vincennes" "America/Indiana/Winamac"
> [137] "America/Indianapolis" "America/Inuvik"
> [139] "America/Iqaluit" "America/Jamaica"
> [141] "America/Jujuy" "America/Juneau"
> [143] "America/Kentucky/Louisville" "America/Kentucky/Monticello"
> [145] "America/Knox_IN" "America/Kralendijk"
> [147] "America/La_Paz" "America/Lima"
> [149] "America/Los_Angeles" "America/Louisville"
> [151] "America/Lower_Princes" "America/Maceio"
> [153] "America/Managua" "America/Manaus"
> [155] "America/Marigot" "America/Martinique"
> [157] "America/Matamoros" "America/Mazatlan"
> [159] "America/Mendoza" "America/Menominee"
> [161] "America/Merida" "America/Metlakatla"
> [163] "America/Mexico_City" "America/Miquelon"
> [165] "America/Moncton" "America/Monterrey"
> [167] "America/Montevideo" "America/Montreal"
> [169] "America/Montserrat" "America/Nassau"
> [171] "America/New_York" "America/Nipigon"
> [173] "America/Nome" "America/Noronha"
> [175] "America/North_Dakota/Beulah" "America/North_Dakota/Center"
> [177] "America/North_Dakota/New_Salem" "America/Nuuk"
> [179] "America/Ojinaga" "America/Panama"
> [181] "America/Pangnirtung" "America/Paramaribo"
> [183] "America/Phoenix" "America/Port_of_Spain"
> [185] "America/Port-au-Prince" "America/Porto_Acre"
> [187] "America/Porto_Velho" "America/Puerto_Rico"
> [189] "America/Punta_Arenas" "America/Rainy_River"
> [191] "America/Rankin_Inlet" "America/Recife"
> [193] "America/Regina" "America/Resolute"
> [195] "America/Rio_Branco" "America/Rosario"
> [197] "America/Santa_Isabel" "America/Santarem"
> [199] "America/Santiago" "America/Santo_Domingo"
> [201] "America/Sao_Paulo" "America/Scoresbysund"
> [203] "America/Shiprock" "America/Sitka"
> [205] "America/St_Barthelemy" "America/St_Johns"
> [207] "America/St_Kitts" "America/St_Lucia"
> [209] "America/St_Thomas" "America/St_Vincent"
> [211] "America/Swift_Current" "America/Tegucigalpa"
> [213] "America/Thule" "America/Thunder_Bay"
> [215] "America/Tijuana" "America/Toronto"
> [217] "America/Tortola" "America/Vancouver"
> [219] "America/Virgin" "America/Whitehorse"
> [221] "America/Winnipeg" "America/Yakutat"
> [223] "America/Yellowknife" "Antarctica/Casey"
> [225] "Antarctica/Davis" "Antarctica/DumontDUrville"
> [227] "Antarctica/Macquarie" "Antarctica/Mawson"
> [229] "Antarctica/McMurdo" "Antarctica/Palmer"
> [231] "Antarctica/Rothera" "Antarctica/South_Pole"
> [233] "Antarctica/Syowa" "Antarctica/Troll"
> [235] "Antarctica/Vostok" "Arctic/Longyearbyen"
> [237] "Asia/Aden" "Asia/Almaty"
> [239] "Asia/Amman" "Asia/Anadyr"
> [241] "Asia/Aqtau" "Asia/Aqtobe"
> [243] "Asia/Ashgabat" "Asia/Ashkhabad"
> [245] "Asia/Atyrau" "Asia/Baghdad"
> [247] "Asia/Bahrain" "Asia/Baku"
> [249] "Asia/Bangkok" "Asia/Barnaul"
> [251] "Asia/Beirut" "Asia/Bishkek"
> [253] "Asia/Brunei" "Asia/Calcutta"
> [255] "Asia/Chita" "Asia/Choibalsan"
> [257] "Asia/Chongqing" "Asia/Chungking"
> [259] "Asia/Colombo" "Asia/Dacca"
> [261] "Asia/Damascus" "Asia/Dhaka"
> [263] "Asia/Dili" "Asia/Dubai"
> [265] "Asia/Dushanbe" "Asia/Famagusta"
> [267] "Asia/Gaza" "Asia/Harbin"
> [269] "Asia/Hebron" "Asia/Ho_Chi_Minh"
> [271] "Asia/Hong_Kong" "Asia/Hovd"
> [273] "Asia/Irkutsk" "Asia/Istanbul"
> [275] "Asia/Jakarta" "Asia/Jayapura"
> [277] "Asia/Jerusalem" "Asia/Kabul"
> [279] "Asia/Kamchatka" "Asia/Karachi"
> [281] "Asia/Kashgar" "Asia/Kathmandu"
> [283] "Asia/Katmandu" "Asia/Khandyga"
> [285] "Asia/Kolkata" "Asia/Krasnoyarsk"
> [287] "Asia/Kuala_Lumpur" "Asia/Kuching"
> [289] "Asia/Kuwait" "Asia/Macao"
> [291] "Asia/Macau" "Asia/Magadan"
> [293] "Asia/Makassar" "Asia/Manila"
> [295] "Asia/Muscat" "Asia/Nicosia"
> [297] "Asia/Novokuznetsk" "Asia/Novosibirsk"
> [299] "Asia/Omsk" "Asia/Oral"
> [301] "Asia/Phnom_Penh" "Asia/Pontianak"
> [303] "Asia/Pyongyang" "Asia/Qatar"
> [305] "Asia/Qostanay" "Asia/Qyzylorda"
> [307] "Asia/Rangoon" "Asia/Riyadh"
> [309] "Asia/Saigon" "Asia/Sakhalin"
> [311] "Asia/Samarkand" "Asia/Seoul"
> [313] "Asia/Shanghai" "Asia/Singapore"
> [315] "Asia/Srednekolymsk" "Asia/Taipei"
> [317] "Asia/Tashkent" "Asia/Tbilisi"
> [319] "Asia/Tehran" "Asia/Tel_Aviv"
> [321] "Asia/Thimbu" "Asia/Thimphu"
> [323] "Asia/Tokyo" "Asia/Tomsk"
> [325] "Asia/Ujung_Pandang" "Asia/Ulaanbaatar"
> [327] "Asia/Ulan_Bator" "Asia/Urumqi"
> [329] "Asia/Ust-Nera" "Asia/Vientiane"
> [331] "Asia/Vladivostok" "Asia/Yakutsk"
> [333] "Asia/Yangon" "Asia/Yekaterinburg"
> [335] "Asia/Yerevan" "Atlantic/Azores"
> [337] "Atlantic/Bermuda" "Atlantic/Canary"
> [339] "Atlantic/Cape_Verde" "Atlantic/Faeroe"
> [341] "Atlantic/Faroe" "Atlantic/Jan_Mayen"
> [343] "Atlantic/Madeira" "Atlantic/Reykjavik"
> [345] "Atlantic/South_Georgia" "Atlantic/St_Helena"
> [347] "Atlantic/Stanley" "Australia/ACT"
> [349] "Australia/Adelaide" "Australia/Brisbane"
> [351] "Australia/Broken_Hill" "Australia/Canberra"
> [353] "Australia/Currie" "Australia/Darwin"
> [355] "Australia/Eucla" "Australia/Hobart"
> [357] "Australia/LHI" "Australia/Lindeman"
> [359] "Australia/Lord_Howe" "Australia/Melbourne"
> [361] "Australia/North" "Australia/NSW"
> [363] "Australia/Perth" "Australia/Queensland"
> [365] "Australia/South" "Australia/Sydney"
> [367] "Australia/Tasmania" "Australia/Victoria"
> [369] "Australia/West" "Australia/Yancowinna"
> [371] "Brazil/Acre" "Brazil/DeNoronha"
> [373] "Brazil/East" "Brazil/West"
> [375] "Canada/Atlantic" "Canada/Central"
> [377] "Canada/Eastern" "Canada/Mountain"
> [379] "Canada/Newfoundland" "Canada/Pacific"
> [381] "Canada/Saskatchewan" "Canada/Yukon"
> [383] "CET" "Chile/Continental"
> [385] "Chile/EasterIsland" "CST6CDT"
> [387] "Cuba" "EET"
> [389] "Egypt" "Eire"
> [391] "EST" "EST5EDT"
> [393] "Etc/GMT" "Etc/GMT-0"
> [395] "Etc/GMT-1" "Etc/GMT-10"
> [397] "Etc/GMT-11" "Etc/GMT-12"
> [399] "Etc/GMT-13" "Etc/GMT-14"
> [401] "Etc/GMT-2" "Etc/GMT-3"
> [403] "Etc/GMT-4" "Etc/GMT-5"
> [405] "Etc/GMT-6" "Etc/GMT-7"
> [407] "Etc/GMT-8" "Etc/GMT-9"
> [409] "Etc/GMT+0" "Etc/GMT+1"
> [411] "Etc/GMT+10" "Etc/GMT+11"
> [413] "Etc/GMT+12" "Etc/GMT+2"
> [415] "Etc/GMT+3" "Etc/GMT+4"
> [417] "Etc/GMT+5" "Etc/GMT+6"
> [419] "Etc/GMT+7" "Etc/GMT+8"
> [421] "Etc/GMT+9" "Etc/GMT0"
> [423] "Etc/Greenwich" "Etc/UCT"
> [425] "Etc/Universal" "Etc/UTC"
> [427] "Etc/Zulu" "Europe/Amsterdam"
> [429] "Europe/Andorra" "Europe/Astrakhan"
> [431] "Europe/Athens" "Europe/Belfast"
> [433] "Europe/Belgrade" "Europe/Berlin"
> [435] "Europe/Bratislava" "Europe/Brussels"
> [437] "Europe/Bucharest" "Europe/Budapest"
> [439] "Europe/Busingen" "Europe/Chisinau"
> [441] "Europe/Copenhagen" "Europe/Dublin"
> [443] "Europe/Gibraltar" "Europe/Guernsey"
> [445] "Europe/Helsinki" "Europe/Isle_of_Man"
> [447] "Europe/Istanbul" "Europe/Jersey"
> [449] "Europe/Kaliningrad" "Europe/Kiev"
> [451] "Europe/Kirov" "Europe/Kyiv"
> [453] "Europe/Lisbon" "Europe/Ljubljana"
> [455] "Europe/London" "Europe/Luxembourg"
> [457] "Europe/Madrid" "Europe/Malta"
> [459] "Europe/Mariehamn" "Europe/Minsk"
> [461] "Europe/Monaco" "Europe/Moscow"
> [463] "Europe/Nicosia" "Europe/Oslo"
> [465] "Europe/Paris" "Europe/Podgorica"
> [467] "Europe/Prague" "Europe/Riga"
> [469] "Europe/Rome" "Europe/Samara"
> [471] "Europe/San_Marino" "Europe/Sarajevo"
> [473] "Europe/Saratov" "Europe/Simferopol"
> [475] "Europe/Skopje" "Europe/Sofia"
> [477] "Europe/Stockholm" "Europe/Tallinn"
> [479] "Europe/Tirane" "Europe/Tiraspol"
> [481] "Europe/Ulyanovsk" "Europe/Uzhgorod"
> [483] "Europe/Vaduz" "Europe/Vatican"
> [485] "Europe/Vienna" "Europe/Vilnius"
> [487] "Europe/Volgograd" "Europe/Warsaw"
> [489] "Europe/Zagreb" "Europe/Zaporozhye"
> [491] "Europe/Zurich" "Factory"
> [493] "GB" "GB-Eire"
> [495] "GMT" "GMT-0"
> [497] "GMT+0" "GMT0"
> [499] "Greenwich" "Hongkong"
> [501] "HST" "Iceland"
> [503] "Indian/Antananarivo" "Indian/Chagos"
> [505] "Indian/Christmas" "Indian/Cocos"
> [507] "Indian/Comoro" "Indian/Kerguelen"
> [509] "Indian/Mahe" "Indian/Maldives"
> [511] "Indian/Mauritius" "Indian/Mayotte"
> [513] "Indian/Reunion" "Iran"
> [515] "Israel" "Jamaica"
> [517] "Japan" "Kwajalein"
> [519] "Libya" "MET"
> [521] "Mexico/BajaNorte" "Mexico/BajaSur"
> [523] "Mexico/General" "MST"
> [525] "MST7MDT" "Navajo"
> [527] "NZ" "NZ-CHAT"
> [529] "Pacific/Apia" "Pacific/Auckland"
> [531] "Pacific/Bougainville" "Pacific/Chatham"
> [533] "Pacific/Chuuk" "Pacific/Easter"
> [535] "Pacific/Efate" "Pacific/Enderbury"
> [537] "Pacific/Fakaofo" "Pacific/Fiji"
> [539] "Pacific/Funafuti" "Pacific/Galapagos"
> [541] "Pacific/Gambier" "Pacific/Guadalcanal"
> [543] "Pacific/Guam" "Pacific/Honolulu"
> [545] "Pacific/Johnston" "Pacific/Kanton"
> [547] "Pacific/Kiritimati" "Pacific/Kosrae"
> [549] "Pacific/Kwajalein" "Pacific/Majuro"
> [551] "Pacific/Marquesas" "Pacific/Midway"
> [553] "Pacific/Nauru" "Pacific/Niue"
> [555] "Pacific/Norfolk" "Pacific/Noumea"
> [557] "Pacific/Pago_Pago" "Pacific/Palau"
> [559] "Pacific/Pitcairn" "Pacific/Pohnpei"
> [561] "Pacific/Ponape" "Pacific/Port_Moresby"
> [563] "Pacific/Rarotonga" "Pacific/Saipan"
> [565] "Pacific/Samoa" "Pacific/Tahiti"
> [567] "Pacific/Tarawa" "Pacific/Tongatapu"
> [569] "Pacific/Truk" "Pacific/Wake"
> [571] "Pacific/Wallis" "Pacific/Yap"
> [573] "Poland" "Portugal"
> [575] "PRC" "PST8PDT"
> [577] "ROC" "ROK"
> [579] "Singapore" "Turkey"
> [581] "UCT" "Universal"
> [583] "US/Alaska" "US/Aleutian"
> [585] "US/Arizona" "US/Central"
> [587] "US/East-Indiana" "US/Eastern"
> [589] "US/Hawaii" "US/Indiana-Starke"
> [591] "US/Michigan" "US/Mountain"
> [593] "US/Pacific" "US/Samoa"
> [595] "UTC" "W-SU"
> [597] "WET" "Zulu"
> attr(,"Version")
> [1] "2025b"Changing Time Zones
There are two ways you may want to change the time zone:
Keep instant in time, change display
x <- ymd_hms("2024-06-01 12:00:00", tz = "America/New_York")
x
with_tz(x, tzone = "Australia/Lord_Howe")- 1
-
The
+1030offset is the difference relative toUTC(functionally similar to Greenwich Mean Time) which is2024-06-01 16:00:00 UTCin this example.
> [1] "2024-06-01 12:00:00 EDT"
> [1] "2024-06-02 02:30:00 +1030"Change underlying instant in time
y <- ymd_hms("2024-06-01 9:00:00", tz = "America/Los_Angeles")
y
force_tz(y, tzone = "Australia/Lord_Howe")- 2
- In this case the time zone was labelled incorrectly so by forcing the correct time zone we changed the underlying instant in time.
> [1] "2024-06-01 09:00:00 PDT"
> [1] "2024-06-01 09:00:00 +1030"Default Time Zones
Time zones in R only control printing of date/time objects. Unless otherwise specified, lubridate always uses UTC1.
Operations that combine date-times, like c(), will often drop the time zone. In that case, the date-times will display in the time zone of the first element:
- 1
- EEST = Eastern European Summer Time
> [1] "2024-06-01 14:00:00 EEST"- 2
- CDT = Central Daylight Time
> [1] "2024-06-01 14:00:00 CDT"- 3
- WAT = West Africa Time
> [1] "2024-06-01 14:00:00 WAT"Lab
Importing & Tidying Data
- Go to the Lecture 5 Homepage and click on the link
Religion & Incomeunder the Data section. - Click File > Save to download this data to the same folder where your source document1 will be saved for this lab.
- Read in your data using the appropriate function from
readr. - Pivot your data to make it tidy2.
- Turn two of the variables into factors3.
- Excluding the income category
Don't know/refused, which religion-income combination has the largest frequency?4
Answers
Click File > Save to download this data to the same folder where your source document1 will be saved for this lab.
Read in your data using the appropriate function from readr.
religion_income <- read_csv(file = "data/religion-income.csv",
col_types = c("f", rep("i", 10)))
glimpse(religion_income)- 1
- If you already know the data type for your variables you can explicitly read them in as such (i.e. in this case we’d want religion to be a factor since it is a categorical variable.)
> Rows: 18
> Columns: 11
> $ religion <fct> Agnostic, Atheist, Buddhist, Catholic, Don’t know…
> $ `<$10k` <dbl> 27, 12, 27, 418, 15, 575, 1, 228, 20, 19, 289, 29…
> $ `$10-20k` <dbl> 34, 27, 21, 617, 14, 869, 9, 244, 27, 19, 495, 40…
> $ `$20-30k` <dbl> 60, 37, 30, 732, 15, 1064, 7, 236, 24, 25, 619, 4…
> $ `$30-40k` <dbl> 81, 52, 34, 670, 11, 982, 9, 238, 24, 25, 655, 51…
> $ `$40-50k` <dbl> 76, 35, 33, 638, 10, 881, 11, 197, 21, 30, 651, 5…
> $ `$50-75k` <dbl> 137, 70, 58, 1116, 35, 1486, 34, 223, 30, 95, 110…
> $ `$75-100k` <dbl> 122, 73, 62, 949, 21, 949, 47, 131, 15, 69, 939, …
> $ `$100-150k` <dbl> 109, 59, 39, 792, 17, 723, 48, 81, 11, 87, 753, 4…
> $ `>150k` <dbl> 84, 74, 53, 633, 18, 414, 54, 78, 6, 151, 634, 42…
> $ `Don't know/refused` <dbl> 96, 76, 54, 1489, 116, 1529, 37, 339, 37, 162, 13…Answers
Pivot your data to make it tidy1.
> # A tibble: 180 × 3
> religion income frequency
> <fct> <chr> <dbl>
> 1 Agnostic <$10k 27
> 2 Agnostic $10-20k 34
> 3 Agnostic $20-30k 60
> 4 Agnostic $30-40k 81
> 5 Agnostic $40-50k 76
> 6 Agnostic $50-75k 137
> 7 Agnostic $75-100k 122
> 8 Agnostic $100-150k 109
> 9 Agnostic >150k 84
> 10 Agnostic Don't know/refused 96
> # ℹ 170 more rowsAnswers
Turn two of the variables into factors1.
Answers
Turn two of the variables into factors1.
religion_income_tidy <- religion_income |>
pivot_longer(cols = !religion,
names_to = "income",
values_to = "frequency") |>
mutate(income = fct(income,
levels = c("Don't know/refused", "<$10k", "$10-20k",
"$20-30k", "$30-40k", "$40-50k", "$50-75k",
"$75-100k", "$100-150k", ">150k")),
religion = fct(religion))- 1
- If we hadn’t initially read in religion as a factor, we’d need to recode it as one during this step.
Answers
> # A tibble: 180 × 3
> religion income frequency
> <fct> <fct> <dbl>
> 1 Agnostic <$10k 27
> 2 Agnostic $10-20k 34
> 3 Agnostic $20-30k 60
> 4 Agnostic $30-40k 81
> 5 Agnostic $40-50k 76
> 6 Agnostic $50-75k 137
> 7 Agnostic $75-100k 122
> 8 Agnostic $100-150k 109
> 9 Agnostic >150k 84
> 10 Agnostic Don't know/refused 96
> # ℹ 170 more rowsAnswers
Excluding the income category Don't know/refused, which religion-income combination has the largest frequency?1
Answers
Excluding the income category Don't know/refused, which religion-income combination has the largest frequency?1
Data visualization
Code
library(ggthemes)
heatmap <- religion_income_tidy |>
filter(income != "Don't know/refused") |>
ggplot(aes(x = income, y = religion, fill = frequency)) +
geom_raster() +
scale_fill_distiller("Frequency", palette = "Greens", direction = 1) +
labs(title = "Heatmap of Religion & Income",
x = "Income Level",
y = "Religious Affiliation") +
theme_tufte(base_size = 18)